math
yeah the math stuff
Calculus
tags math calculus
Differential
example
intergrant
example
Taylor series 泰勒展開式
find sin(x) Taylor series
Formal Language
tags: math
automata
- DFA(Deterministic Finite Automation)
- NFA(Nondeterministic Finite Automation)
- PDA(Push Down Automation)

DFA / NFA
DFA
regular language
regular expression
closure properties
pumping lemma for regular languages
DFA == regular language
For every NFA there is a regular expression such that
L(q,p,k){w ∈ | there is a run of M on w from state q to state p and let passing through states set length < k}.

DFA to regular language
state removal method

brzozowski algebraic method

PDA

context free language
pumping lemma for CFL
closure properties
Formal Language
tags: math
automata
- DFA(Deterministic Finite Automation)
- NFA(Nondeterministic Finite Automation)
- PDA(Push Down Automation)
DFA / NFA
DFA
regular language
regular expression
closure properties
pumping lemma for regular languages
DFA == regular language
For every NFA there is a regular expression such that
L(q,p,k){w ∈ | there is a run of M on w from state q to state p and let passing through states set length < k}.
DFA to regular language
state removal method
brzozowski algebraic method
PDA
context free language
pumping lemma for CFL
closure properties
hw1
1.a
1.b
1.c
1.d
1.e
2.a
2.b
3.a
3.b
3.c
3.d
3.e
4.a
4.b
4.c
5
If is regular, then is also regular because is but remove the final state that be passing though another final state.
for example
6.a
6.b
6.c
6.d
6.e
6.f
6.g
If is regular language then it can convert to DFA.
Divide a DFA to equeal part still are DFA which make it still regular.
6.h
6.i
6.j
not regular
7.a
7.b
7.c
7.d
8.a
8.b
8.c
8.d
is DFA by definition
is base on but modify function and remove some state and final state. So it still a DFA
8.e
9.a
Each symbols need 2 state to record is even or odd state and additional one state for init state; total 2n+1 state.
9.b
Because DFA each state have determine result to next state by input. We need to know all symbols is even or odd in one state. So each symbols have two possible (even or odd) lead to state
9.c
10.a
prove are morphism
F-map
B-map
10.b
10.c
tags math linear algebra
linear algebra
matrix
| Column 1 | Column 2 | Column 3 | |
|---|---|---|---|
| Row1 | value | value | value |
| Row2 | value | value | value |
| Row3 | value | value | value |
diagonal 對角 commutative law associative law distributive law
sample
乘積
反矩陣
identity matrix
transpose matrix
inner change (change row)
math to matrix
reduced echelon form(gaussian elimination)
vector equation and matrix equation
span
linear dependence
linear depandence vs. span:
echelon form
vector equation
span R^4
NO,did not have pivot point in row3 and row4
linear independence?
NO,did not have pivot point in column 3
transform
one-to-one
onto
linear transformation
vectorspace
child space
null space
columns space
rows space
rank nullity
![]()
rank
the number of non-zero pivot column
nullity/kernel
the number of zero pivot column
Eigenvector and Eigenvalue
eigen value
eigen vector
diagonalization
orthogonal
dot
|A|
vector
matrix
orthogonal vs orthonormal
orthogonal matrix
orthonormal
find orth basis(gram-schmidt process)
derivative of a Matrix
projection
curve fitting | regression | normal equation
way 1
way 2
way 3
math-modeling
title: 循環賽
tags: Templates, Talk description: View the slide with “Slide Mode”.
循環賽
題目
下圖為五位選手的比賽結果 a->b表示 a 獲勝
矩陣
循環
循環
tags math matrix algebra
matrix algebra
multiplication
dot product
by columns
by row
by block
matrix form of gaussian elimination
actually the row reduce from the there are matrix multiplication as well
Subtracting 2 times the row of A from the row of A
for example
revert U to A
are elimination operation matrix
is Lower triangular matrix
is Upper triangular matrix
Symmetric matrix
projection matrix(project vector to columns space)
projection vector on vector
projection matrix
property
- symmetric
Pseudoinverse matrix
determinant
SVD
polar decomposition
tags math matrix algebra
matrix algebra
multiplication
dot product
by columns
by row
by block
matrix form of gaussian elimination
actually the row reduce from the there are matrix multiplication as well
Subtracting 2 times the row of A from the row of A
for example
revert U to A
are elimination operation matrix
is Lower triangular matrix
is Upper triangular matrix
Symmetric matrix
projection matrix(project vector to columns space)
projection vector on vector
projection matrix
property
- symmetric
Pseudoinverse matrix
determinant
SVD
polar decomposition
Q2
1
2
4
5
Q3
1
2
3
4
5
6
7
8
9
10
11
- (a) real eigenvalue
- (b) real part < 0
- (c) eigenvalue 1 or -1
- (d) eigenvalue =1
- (e)
- (f) eigenvalue =0
12
13
14
15
16
a
b
c
18
hw2 110590049
tags probability
problem 1
problem 2
problem 3
problem 4
problem 5
Evey level at least have one people leave so only 3 people can chose leave level freely
problem 6
(a)
(b)
(c)
problem 7
problem 8
hw2 110590049
tags probability
problem 1
problem 2
problem 3
problem 4
problem 5
Evey level at least have one people leave so only 3 people can chose leave level freely
problem 6
(a)
(b)
(c)
problem 7
problem 8
hw3 110590049
tags probability
1.a
1.b
2
3
4
5
6
7.a
7.b
8
9
10
11
hw4 110590049
tags probability
1
2
3
4
5
6
7
hw5 110590049
tags probability
1
2
3
4
5
6
7
8
9
hw6 110590049
tags probability
1
2
3
4
5
6
7
8
9
10
hw7 110590049
tags probability
1.a
1.b
2.a
2.b
3
4
5
6
hw8 110590049
tags probability
1
2
3
4
5
6
7
8
9
hw9 110590049
tags probability
1.a
1.b
1.c
1.d
2
3.a
3.b
3.c
3.d
3.e
4
5
6
7.a
7.b
7.c
SIGNALS and SYSTEMS
CT vs DT
CT(continuous-time)
For a continuous-time (CT) signal, the independent variable is
always enclosed by a parenthesis
Example:
DT(discrete-time)
For a discrete-time (DT) signal, the independent variable is always
enclosed by a brackets
Example:
Signal Energy and Power
Energy
average power
ex1
ex2
odd vs even
even
odd
some prove
unit step function and unit impulse function
| unit step | unit impules | |
|---|---|---|
| discrcte | ||
| continouse | ||
basic system properties
memory and memoryless
memoryless systems
only the current signal
memory systems
only the current signal
invertibility
function is invertable
causality
only the current and past signal are relate then it is causal system
causal systems
non-causal systems
stability (BIBO stable )
can find BIBO(bounded-input and bounded-output) in another word the function is diverage or not.
BIBO stable
BIBO unstable
time invariance
the function shift input will only shift and dont have any effect
example
linearity
if then is linearty
test
| memoryless | stable | causal | linaer | time invariant | |
|---|---|---|---|---|---|
| ✅ | ✅ | ✅ | ❌ | ✅ | |
| ✅ | ✅ | ✅ | ✅ | ❌ | |
| ❌ | ✅ | ❌ | ✅ | ❌ | |
| ❌ | ✅ | ❌ | ✅ | ✅ | |
| ❌ | ✅ | ❌ | ✅ | ❌ | |
| ✅ | ✅ | ✅ | ✅ | ✅ |
complex plane
exponential signal & sinusoidal signal
| C is real | C is complex | |
|---|---|---|
| a is real | ||
| a is imaginary | ||
| a is complex |
periods
CT
example
DT
fundamental period is integer that for all integer
have to be integer.
not every “sinusoidal signal” have
example
convolution
CT
DT
| h\x | x[n] | 0 | 1 | 2 | 3 | 3 |
|---|---|---|---|---|---|---|
| h[n] | 1 | 0.5 | 0.25 | 0.125 | 0.0625 | |
| 0 | 1 | 1 | 0.5 | 0.25 | 0.125 | 0.0625 |
| 1 | 0.5 | 0.5 | 0.25 | 0.125 | 0.0625 | 0.03125 |
| 2 | 0.25 | 0.5 | 0.125 | 0.0625 | 0.03125 | 0.015625 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
commutative
distributive
associative
LTI(Linear Time-Invariant)
Linear
Time-invariant
LTI systems and convolution
stability for LTI Systems
Unit Step Response of an LTI System
CT
DT
eigen function and eigen value of LTI systems
The response of an LTI system to a eigen function is the same eigen function with only a change in amplitude(eigen value)
The Response of LTI Systems to Complex Exponential Signals
example
system
delay system
difference system
accumulation system
example
SIGNALS and SYSTEMS
CT vs DT
CT(continuous-time)
For a continuous-time (CT) signal, the independent variable is
always enclosed by a parenthesis
Example:
DT(discrete-time)
For a discrete-time (DT) signal, the independent variable is always
enclosed by a brackets
Example:
Signal Energy and Power
Energy
average power
ex1
ex2
odd vs even
even
odd
some prove
unit step function and unit impulse function
| unit step | unit impules | |
|---|---|---|
| discrcte | ||
| continouse | ||
basic system properties
memory and memoryless
memoryless systems
only the current signal
memory systems
only the current signal
invertibility
function is invertable
causality
only the current and past signal are relate then it is causal system
causal systems
non-causal systems
stability (BIBO stable )
can find BIBO(bounded-input and bounded-output) in another word the function is diverage or not.
BIBO stable
BIBO unstable
time invariance
the function shift input will only shift and dont have any effect
example
linearity
if then is linearty
test
| memoryless | stable | causal | linaer | time invariant | |
|---|---|---|---|---|---|
| ✅ | ✅ | ✅ | ❌ | ✅ | |
| ✅ | ✅ | ✅ | ✅ | ❌ | |
| ❌ | ✅ | ❌ | ✅ | ❌ | |
| ❌ | ✅ | ❌ | ✅ | ✅ | |
| ❌ | ✅ | ❌ | ✅ | ❌ | |
| ✅ | ✅ | ✅ | ✅ | ✅ |
complex plane
exponential signal & sinusoidal signal
| C is real | C is complex | |
|---|---|---|
| a is real | ||
| a is imaginary | ||
| a is complex |
periods
CT
example
DT
fundamental period is integer that for all integer
have to be integer.
not every “sinusoidal signal” have
example
convolution
CT
DT
| h\x | x[n] | 0 | 1 | 2 | 3 | 3 |
|---|---|---|---|---|---|---|
| h[n] | 1 | 0.5 | 0.25 | 0.125 | 0.0625 | |
| 0 | 1 | 1 | 0.5 | 0.25 | 0.125 | 0.0625 |
| 1 | 0.5 | 0.5 | 0.25 | 0.125 | 0.0625 | 0.03125 |
| 2 | 0.25 | 0.5 | 0.125 | 0.0625 | 0.03125 | 0.015625 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
commutative
distributive
associative
LTI(Linear Time-Invariant)
Linear
Time-invariant
LTI systems and convolution
stability for LTI Systems
Unit Step Response of an LTI System
CT
DT
eigen function and eigen value of LTI systems
The response of an LTI system to a eigen function is the same eigen function with only a change in amplitude(eigen value)
The Response of LTI Systems to Complex Exponential Signals
example
system
delay system
difference system
accumulation system
example
signals and systems mid
2
odd signal of is
3
a
odd signal
b
odd signal
even signal
product of and is still are odd signal since
c
4
| linear | time invariant | |
|---|---|---|
| no | no | |
| yes | yes | |
| yes | no |
5
| period | |
|---|---|
6
| memoryless | time invariant | linear | causal | stable | |
|---|---|---|---|---|---|
| ❌ | ✅ | ✅ | ✅ | ✅ | |
| ❌ | ✅ | ✅ | ✅ | ✅ | |
| ✅ | ✅ | ❌ | ✅ | ✅ | |
| ❌ | ✅ | ❌ | ✅ | ✅ |
signals and systems final
1
2
3
3.a
3.b
yes
3.c
yes
4
4.a
computer science
compiler

lexical analysis

follow

first

nullity
regex to DFA

parser

arithmetic expressions
example
look like this
Derivation

context free grammar
The language defined by a context-free grammar
ambiguous grammar
give int + int * int
left derivation
right derivation

Non-ambiguous grammar
give int + int * int * int

bottom-up parsing
- scan the input from left to right
- look for right-hand sides of production rules to build the derivation tree from bottom to top

LR parsing (Knuth, 1965)
Using an automaton and considering the first k tokens of the input;
this is called LR(k) analysis (LR means “Left to right scanning, Rightmost derivation”)

LR table

example

Construction of the automation and the table
NULL
Let .
holds if and only if we can derive from , i.e.,
FIRST
Let .
is the set of all terminals starting words derived from , i.e.,
FOLLOW
Let .
is the set of all terminals that may appear after in a derivation, i.e.,




compiler
lexical analysis
follow
first
nullity
regex to DFA
parser
arithmetic expressions
example
look like this
Derivation
context free grammar
The language defined by a context-free grammar
ambiguous grammar
give int + int * int
left derivation
right derivation
Non-ambiguous grammar
give int + int * int * int
bottom-up parsing
- scan the input from left to right
- look for right-hand sides of production rules to build the derivation tree from bottom to top
LR parsing (Knuth, 1965)
Using an automaton and considering the first k tokens of the input;
this is called LR(k) analysis (LR means “Left to right scanning, Rightmost derivation”)
LR table
example
Construction of the automation and the table
NULL
Let .
holds if and only if we can derive from , i.e.,
FIRST
Let .
is the set of all terminals starting words derived from , i.e.,
FOLLOW
Let .
is the set of all terminals that may appear after in a derivation, i.e.,
hw0
(*print_endline "Hello, World!"*)
let width=32;;
let height=16;;
(* Exercise 1 *)
(* Exercise 1.a*)
let rec fact n=
if n<=1 then
1
else
n*fact(n-1);;
let p_w= "1.a fact(5)="^ string_of_int (fact(5) );;
print_endline p_w;;
(* Exercise 1.b*)
let rec nb_bit_pos n=
if n=0 then
0
else if (n land 1 = 1) then
1 + nb_bit_pos( n lsr 1)
else
nb_bit_pos( n lsr 1);;
let p_w= "1.b nb_bit_pos(5)=" ^ string_of_int (nb_bit_pos(5) );;
print_endline p_w;;
(* Exercise 2*)
let fibo n=
let rec aux n a b=
if n=0 then
a
else
aux (n-1) b (a+b)
in
aux n 0 1
let p_w= "2. fibo(6)="^ string_of_int (fibo(6));;
print_endline p_w;;
(* Exercise 3 *)
(* Exercise 3.a *)
let palindrome m =
let len=String.length m in
let vaild= ref true in
for i = 0 to (len lsr 1) do
if String.get m i <> String.get m (len-1-i) then
vaild:=false
done;
!vaild
let p_w= "3.a palindrome('aba')="^ string_of_bool (palindrome("aba")) ;;
print_endline p_w;;
(* Exercise 3.b*)
let compare m1 m2 =
let len1=String.length m1 in
let len2=String.length m2 in
let rec check i=
if (i < len1) && (i < len2 )then
let c1 =String.get m1 i in
let c2 =String.get m2 i in
if c1 = c2 then
check(i+1)
else if c1 < c2 then
true
else
false
else if len1 == len2 && i == len1 then
false
else if i < len1 then
false
else
true
in
check 0
let p_w= "3.b compare('ab','abc')="^ string_of_bool (compare "ab" "abc") ;;
print_endline p_w;;
(* Exercise 3.c *)
let factor m1 m2 =
let len1=String.length m1 in
let len2=String.length m2 in
let vaild =ref false in
for i = 0 to len2-len1 do
let sub=String.sub m2 i len1 in
if sub = m1 then
vaild:=true
done;
!vaild
let p_w= "3.c factor('ab','abc')="^ string_of_bool (factor "ac" "abcdfg") ;;
print_endline p_w;;
(* Exercise 4 *)
let string_of_list l = "[" ^ (String.concat "," (List.map string_of_int l)) ^ "]"
let slice l start stop =
let rec aux i acc = function
| [] -> List.rev acc (* If list is empty, return the reversed accumulator *)
| hd :: tl ->
if i >= stop then List.rev acc (* Stop when index reaches 'stop' *)
else if i >= start then aux (i + 1) (hd :: acc) tl (* Add element to accumulator if within slice *)
else aux (i + 1) acc tl (* Continue without adding element *)
in
aux 0 [] l
let split l =
let len = (List.length l) in
let mid = len lsr 1
in
(slice l 0 mid, slice l mid len)
let merge l1 l2 =
let rec aux acc = function
| (h1::t1,h2::t2) ->
if h1 < h2 then
aux (h1::acc) (t1,h2::t2)
else
aux (h2::acc) (h1::t1,t2)
| (h1::t1,[]) -> aux (h1::acc) (t1,[])
| ([],h2::t2) -> aux (h2::acc) ([],t2)
| ([],[]) -> List.rev acc
in
aux [] (l1,l2)
let rec sort ll=
if List.length ll <=1 then
ll
else
let l,r =split ll in
let sl,sr=sort(l),sort(r) in
merge sl sr
let () =
let test_list = [1; 4; 3; 2; 5] in
let l,r =split test_list in
let p_w1= "4. split" ^ string_of_list (test_list) ^"=" ^ string_of_list (l) ^ ","^ string_of_list (r) in
let p_w2= "4. merge" ^ string_of_list (l) ^ ","^ string_of_list (r) ^ "=" ^string_of_list ( merge l r)in
let p_w3= "4. sort" ^ string_of_list (test_list) ^"=" ^ string_of_list (sort test_list) in
print_endline p_w1;
print_endline p_w2;
print_endline p_w3
(* Exercise 5.a *)
let pow m = m * m
let square_sum m =
List.fold_left (+) 0 (List.map pow m)
let () =
let test_list = [1; 2; 3] in
let p_w = "5.a square_sum = " ^ string_of_int (square_sum test_list) in
print_endline p_w
(* Exercise 5.b *)
let find_opt x l =
let rec aux i = function
| [] -> None
| hd :: tl ->
if hd = x then
Some i
else
aux (i + 1) tl (* Check if head equals x, otherwise recurse *)
in
aux 0 l
let find_opt x l=
let (return ,_) =List.fold_left (
fun (out,i) v ->
if v=x && out ==None then
(Some i,i+1)
else
(None,i+1)
)(None,0) l in
return
let unwrap = function
| Some c -> string_of_int c
| None -> "Not found"
let () =
let test_list = [1; 2; 3; 2] in
let result = find_opt 2 test_list in
let p_w = "5.b find_opt 2," ^ string_of_list test_list ^ " = " ^ unwrap result in
print_endline p_w
(* Exercise 6 *)
let rev l =
let rec rev_append acc l =
match l with
| [] -> acc
| h :: t -> rev_append (h :: acc) t
in
rev_append [] l
let map f l =
let rec aux acc l =
match l with
| [] -> List.rev acc (* Reverse the accumulator before returning *)
| h :: t -> aux (f h :: acc) t
in
aux [] l
let () =
(*
let test_list = List.init 1000001 (fun i -> i) in
let r1= rev test_list in
let r2= map (fun x -> x*2)test_list in
*)
let p_w1 = "6. rev ..." in
let p_w2 = "6. map ..." in
print_endline p_w1;
print_endline p_w2
(* Exercise 7 *)
type 'a seq =
| Elt of 'a
| Seq of 'a seq * 'a seq
let (@@) x y = Seq(x, y)
let rec hd x =
match x with
| Elt s -> s
| Seq(s1,s2) -> hd s1
let rec tl l=
let rec aux find ll =
match ll with
| Elt s -> raise (Failure "you entered an empty list")
| Seq (Elt s, Elt s1) ->
if find then
(false,Elt s1)
else
(false, Seq (Elt s, Elt s1))
| Seq (Elt s, s1) ->
if find then
(false,s1)
else
(false, Seq (Elt s, s1))
| Seq (s1, Elt s) ->
let find',ll=aux find s1 in
if find'=false then
(false,Seq (ll, Elt s) )
else
(false,Seq (s1, Elt s) )
| Seq (x1, x2 )->
let find',ll=aux find x1 in
if find'=false then
(false,Seq (ll,x2) )
else
(false,Seq (x1, x2 ))
in
let _,ll=aux true l in
ll
let rec mem v =function
| Elt s -> s=v
| Seq(s1,s2) -> ((mem v s1) || (mem v s2))
let rec rev =function
| Elt s -> Elt s
| Seq(s1,s2) -> Seq((rev s2),(rev s1))
let rec map f = function
| Elt s -> Elt (f s) (* Apply f to the single element *)
| Seq (s1, s2) -> Seq (map f s1, map f s2) (* Recursively map over both sub-sequences *)
let rec fold_left f acc = function
| Elt s -> f acc s (* Apply f to the accumulator and the single element *)
| Seq (s1, s2) ->
let acc' = fold_left f acc s1 in (* Fold over the first sub-sequence *)
fold_left f acc' s2 (* Fold over the second sub-sequence *)
let rec fold_right f seq acc =
match seq with
| Elt s -> f s acc (* Apply f to the single element and the accumulator *)
| Seq (s1, s2) -> fold_right f s1 (fold_right f s2 acc) (* Fold over both sub-sequences *)
let seq2list seq =
let rec aux acc = function
| Elt s -> s :: acc
| Seq (s1, s2) -> aux (aux acc s1) s2
in
List.rev (aux [] seq)
let find_opt x l=
let (return ,_) =fold_left (
fun (out,i) v ->
match out with
| None ->
if v=x then
(Some i,i+1)
else
(None,i+1)
| Some k ->
(out,i+1)
)(None,0) l in
return
let nth x l=
let (return ,_) =fold_left (
fun (out,i) v ->
match out with
| None ->
if i=x then
(Some v,i+1)
else
(None,i+1)
| Some k ->
(out,i+1)
)(None,0) l in
match return with
| None -> raise (Failure "out of range")
| Some v -> v
(*
let print_of_something = function
| Int s -> string_of_int s
| Elt s -> string_of_list [s]
| Seq (s1,s2)-> string_of_list (seq2list s1) ^ string_of_list (seq2list s2)
*)
let () =
let test_seq =
Seq(Seq (Elt 1,Elt 2),Seq (Seq (Elt 3,Elt 4),Elt 5)) in
let test_list= seq2list test_seq in
let p_w1 = "7. hd " ^ string_of_list test_list ^"=" ^ string_of_int (hd test_seq) in
let p_w2 = "7. tl " ^ string_of_list test_list ^"=" ^ string_of_list (seq2list (tl test_seq)) in
let p_w3 = "7. mem" ^ string_of_list test_list ^"=" ^ string_of_bool(mem 5 test_seq) in
let p_w4 = "7. rev" ^ string_of_list test_list ^"=" ^ string_of_list (seq2list ( rev test_seq)) in
let p_w5 = "7. map" ^ string_of_list test_list ^"=" ^ string_of_list (seq2list ( map (fun x -> x *2 )test_seq)) in
let p_w6 = "7. fold_right" ^ string_of_list test_list ^"=" ^ string_of_int( fold_left (+) 0 test_seq ) in
let p_w7 = "7. find_opt " ^ string_of_int 3 ^ string_of_list test_list ^"=" ^ (unwrap( find_opt 3 test_seq ) )in
let p_w8 = "7. nth " ^ string_of_int 3 ^ string_of_list test_list ^"=" ^ (string_of_int( nth 3 test_seq ) )in
print_endline p_w1;
print_endline p_w2;
print_endline p_w3;
print_endline p_w4;
print_endline p_w5;
print_endline p_w6;
print_endline p_w7;
print_endline p_w8
hw1
1
gcc -S exercise1.c -o exercise1.s
sh run.sh exercise1.s
2~5
sh run.sh exercise2.s
sh run.sh exercise3.s
sh run.sh exercise4.s
sh run.sh exercise5.s
sh run.sh exercise6.s
6
gcc -S exercise6.c -o exercise6.s
sh run.sh exercise6.s
7
gcc -S matrix.c -o matrix.s
sh run.sh matrix.s
run.sh
#!/bin/bash
# Check if file is provided
if [ -z "$1" ]; then
echo "Usage: $0 <assembly-file>"
exit 1
fi
# Set the input file
asm_file=$1
# Get the base filename without the extension
base_filename=$(basename "$asm_file" .s)
# Assemble
# nasm -f elf64 "$asm_file" -o "$base_filename.o"
as "$asm_file" -o "$base_filename.o"
if [ $? -ne 0 ]; then
echo "Error: Assembly failed"
exit 1
fi
# Link
gcc -no-pie "$base_filename.o" -o "$base_filename.bin"
if [ $? -ne 0 ]; then
echo "Error: Linking failed"
exit 1
fi
# Execute
./"$base_filename.bin"
1.
.file "exercise1.c"
.text
.section .rodata
.LC0:
.string "n = %d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $42, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 14.2.1 20240910"
.section .note.GNU-stack,"",@progbits
2.
.text
.globl main # make main visible for ld
main:
pushq %rbp # Save base pointer
movq %rsp, %rbp # Set up stack frame
# 4 + 6
movq $4, %rax # Load first operand into RAX
addq $6, %rax # 4 + 6
movq $msg, %rdi # First argument: format string
movq %rax, %rsi # Second argument: result
xorq %rax, %rax # Clear RAX (no floating point args)
call printf # Call printf
# 21 * 2
movq $21, %rax # Load first operand into RAX
imulq $2, %rax # 21 * 2
movq $msg, %rdi # First argument: format string
movq %rax, %rsi # Second argument: result
xorq %rax, %rax # Clear RAX
call printf # Call printf
# 4 + 7 / 2
movq $7, %rax # Load numerator into RAX
xorq %rdx, %rdx # Clear RDX for division
movq $2, %rcx # Load denominator into RCX
idivq %rcx # RAX = RAX / RCX (7 / 2)
addq $4, %rax # Add the result to 4
movq $msg, %rdi # First argument: format string
movq %rax, %rsi # Second argument: result
xorq %rax, %rax # Clear RAX
call printf # Call printf
# 3 - 6 * (10 / 5)
movq $10, %rax # Load numerator into RAX
movq $5, %rcx # Load denominator into RCX
idivq %rcx # RAX = RAX / RCX (10 / 5)
imulq $-6, %rax # RAX = RAX * (-6)
addq $3, %rax # Add 3 to the result
movq $msg, %rdi # First argument: format string
movq %rax, %rsi # Second argument: result
xorq %rax, %rax # Clear RAX (no floating point args)
call printf # Call printf
# Exit
movq $0, %rax # Return code 0
popq %rbp # Restore base pointer
ret # Return from main
.data
msg:
.string "n = %d\n" # Format string for printf
3.
.text
.globl main # make main visible for ld
main:
pushq %rbp # Save base pointer
movq %rsp, %rbp # Set up stack frame
# Evaluate true && false
movq $1, %rax # Load true (1) into RAX
andq $0, %rax # Perform logical AND with false (0)
cmpq $0, %rax # Compare result with 0 (false)
movq $false_msg, %rdi # Assume false by default
movq $true_msg, %rsi # Assume true
cmovne %rdi, %rsi # If result is not 0, use true message
call printf # Call printf
# Evaluate 3 == 4 ? 10 * 2 : 14
movq $3, %rax # Load 3 into RAX
cmpq $4, %rax # Compare RAX with 4
jne not_equal # Jump if not equal (3 != 4)
movq $14, %rax # Load result for else case (14)
jmp print_result # Jump to print result
not_equal:
movq $10, %rax # Load first operand (10)
imulq $2, %rax # Multiply by 2 (10 * 2)
print_result:
movq $int_msg, %rdi # Load format string for integer output
movq %rax, %rsi # Second argument: result (product or 14)
call printf # Call printf
# Evaluate 2 == 3 || 4 <= (2 * 3)
movq $3, %rax # Load 3 into RAX
cmpq $2, %rax # Compare 2 with 3
jne check_second_condition # Jump if 2 != 3
movq $1, %rbx # If 2 == 3, set RBX to true (1)
jmp finish # Jump to finish
check_second_condition:
movq $2, %rcx # Load 2 into RCX
imulq $3, %rcx # Multiply 2 * 3 (result: 6)
movq $4, %rax # Load 4 into RAX
cmpq %rcx, %rax # Compare 4 with 6
jbe less_or_equal # Jump if 4 <= 6
movq $0, %rbx # If not, set RBX to false (0)
jmp finish # Jump to finish
less_or_equal:
movq $1, %rbx # If 4 <= 6, set RBX to true (1)
finish:
cmpq $0, %rbx # Compare RBX with 0 (false)
movq $false_msg, %rdi # Assume false by default
movq $true_msg, %rsi # Assume true
cmovne %rsi, %rdi # If RBX is not zero (true), use true message
call printf # Call printf
# Exit program properly
movq $0, %rax # Return code 0
popq %rbp # Restore base pointer
ret # Return from main
.data
false_msg:
.string "false\n" # String for false output
true_msg:
.string "true\n" # String for true output
int_msg:
.string "%d\n" # Format string for integer output
4.
.text
.globl main # Make main visible for the linker
main:
pushq %rbp # Save base pointer
movq %rsp, %rbp # Set up stack frame
# Load x from memory
movq x(%rip), %rax # Move the value of x (2) into RAX
# y = x * x
imulq %rax, %rax # Multiply x by itself (RAX = RAX * RAX, now RAX = 4)
# Store the result of y in memory
movq %rax, y(%rip) # Move the result (y = 4) into the y variable
# Load x and y from memory
movq x(%rip), %rax # Load x (2) back into RAX
addq y(%rip), %rax # Add y (4) to RAX (RAX = 4 + 2 = 6)
# Prepare for the printf call
movq $result_msg, %rdi # Load the format string into RDI
movq %rax, %rsi # Move the result (6) into RSI
xorq %rax, %rax # Clear RAX for calling printf
call printf # Call printf to print the result
# Exit the program
movq $60, %rax # syscall: exit
xorq %rdi, %rdi # status: 0
syscall # invoke syscall
popq %rbp # Restore base pointer
ret # Return from main
.data # Data section
x: .quad 2 # Allocate x in the data segment, initialized to 2
y: .quad 0 # Allocate y in the data segment, initialized to 0
result_msg: .string "%d\n" # Format string for printf
5
.data
result_msg: .string "%d\n" # Format string for printf
.text
.globl main # Make main visible for the linker
main:
pushq %rbp # Save base pointer
movq %rsp, %rbp # Set up stack frame
### First Instruction: print (let x = 3 in x * x)
# Allocate space for x on the stack
subq $8, %rsp # Reserve 8 bytes on the stack for x
movq $3, (%rsp) # Set x = 3 (store on stack)
# x * x
movq (%rsp), %rax # Load x into RAX
imulq %rax, %rax # Multiply x by itself (RAX = x * x)
# Prepare for the printf call (result is 9)
movq $result_msg, %rdi # Load the format string into RDI
movq %rax, %rsi # Move the result (9) into RSI
xorq %rax, %rax # Clear RAX for calling printf
call printf # Call printf to print the result
# Deallocate space for x
addq $8, %rsp # Free the space allocated for x on the stack
### Second Instruction: print (let x = 3 in ...)
# Allocate space for x on the stack
subq $8, %rsp # Reserve 8 bytes on the stack for x
movq $3, (%rsp) # Set x = 3 (store on stack)
# Inner block: let y = x + x in x * y
subq $8, %rsp # Reserve 8 bytes on the stack for y
movq 8(%rsp), %rax # Load x into RAX (from previous stack slot)
addq %rax, %rax # y = x + x (RAX = x + x)
movq %rax, (%rsp) # Store y on the stack 3
movq 8(%rsp), %rax # Load x into RAX again (from previous stack slot)
imulq (%rsp), %rax # Multiply x * y (RAX = x * y)
movq %rax, (%rsp) # Store y on the stack 18
# Inner block: let z = x + 3 in z / z
subq $8, %rsp # Reserve 8 bytes on the stack for z
movq 16(%rsp), %rcx # Load x into RCX (from previous stack slot)
addq $3, %rcx # z = x + 3 (RCX = x + 3)
movq %rcx, (%rsp) # Store z on the stack
xorq %rdx, %rdx # Clear RDX (for division)
movq (%rsp), %rax # Load z into RAX (z = x + 3)
idivq %rax # z / z (RAX = z / z, which is 1)
# Compute (x * y) + (z / z)
addq %rax, 8(%rsp) # Add z / z (which is 1) to x * y (from earlier)
# Prepare for the printf call (result is 19)
movq $result_msg, %rdi # Load the format string into RDI
movq 8(%rsp), %rsi # Load the result (19) into RSI
xorq %rax, %rax # Clear RAX for calling printf
call printf # Call printf to print the result
# Deallocate space for z, y, and x
addq $24, %rsp # Free the space allocated for z, y, and x
### Exit the program
movq $60, %rax # syscall: exit
xorq %rdi, %rdi # status: 0
syscall # invoke syscall
popq %rbp # Restore base pointer
ret # Return from main
6
#include <stdio.h>
int isqrt(int n)
{
int c = 0, s = 1;
// x^2 = (x-1)^2 + 2(x-1) + 1
do
{
// Increment c and calculate s in one line
s += (++c << 1) + 1;
} while (s <= n); // Single branching instruction here
return c;
}
int main()
{
int n;
for (n = 0; n <= 20; n++)
printf("sqrt(%2d) = %2d\n", n, isqrt(n));
return 0;
}
hw2
open Ast
open Format
(* Exception raised to signal a runtime error *)
exception Error of string
let error s = raise (Error s)
(* Values of Mini-Python.
Two main differences wrt Python:
- We use here machine integers (OCaml type `int`) while Python
integers are arbitrary-precision integers (we could use an OCaml
library for big integers, such as zarith, but we opt for simplicity
here).
- What Python calls a ``list'' is a resizeable array. In Mini-Python,
there is no way to modify the length, so a mere OCaml array can be used.
*)
type value =
| Vnone
| Vbool of bool
| Vint of int
| Vstring of string
| Vlist of value array
(* Print a value on standard output *)
let rec print_value = function
| Vnone -> printf "None"
| Vbool true -> printf "True"
| Vbool false -> printf "False"
| Vint n -> printf "%d" n
| Vstring s -> printf "%s" s
| Vlist a ->
let n = Array.length a in
printf "[";
for i = 0 to n-1 do print_value a.(i); if i < n-1 then printf ", " done;
printf "]"
(* Boolean interpretation of a value
In Python, any value can be used as a Boolean: None, the integer 0,
the empty string, and the empty list are all considered to be
False, and any other value to be True.
*)
let is_false v = match v with
| Vnone
| Vbool false
| Vstring ""
| Vlist [||] -> true
| Vint n -> n = 0
| _ -> false
let is_true v = not (is_false v)
(* We only have global functions in Mini-Python *)
let functions = (Hashtbl.create 16 : (string, ident list * stmt) Hashtbl.t)
(* The following exception is used to interpret `return` *)
exception Return of value
(* Local variables (function parameters and local variables introduced
by assignments) are stored in a hash table that is passed to the
following OCaml functions as parameter `ctx`. *)
type ctx = (string, value) Hashtbl.t
(* Interpreting an expression (returns a value) *)
let compare op n1 n2 = match n1 , n2 with
| int ,_->
match op with
| Beq -> n1 = n2
| Bneq -> n1 <> n2
| Blt -> n1 < n2
| Ble -> n1 <= n2
| Bgt -> n1 > n2
| Bge -> n1 >= n2
| _ -> raise (Error "unsupported operand types")
let rec expr ctx = function
| Ecst Cnone ->
Vnone
| Ecst (Cbool b) ->
Vbool(b)
| Ecst (Cstring s) ->
Vstring s
| Ecst (Cint n) ->
Vint (Int64.to_int n)
(* arithmetic *)
| Ebinop (Badd | Bsub | Bmul | Bdiv | Bmod |
Beq | Bneq | Blt | Ble | Bgt | Bge as op, e1, e2) ->
let v1 = expr ctx e1 in
let v2 = expr ctx e2 in
begin match op, v1, v2 with
(* int *)
| Badd, Vint n1, Vint n2 -> Vint (n1 + n2)
| Bsub, Vint n1, Vint n2 -> Vint (n1 - n2)
| Bmul, Vint n1, Vint n2 -> Vint (n1 * n2)
| Bdiv, Vint n1, Vint n2 -> Vint (n1 / n2)
| Bmod, Vint n1, Vint n2 -> Vint (n1 mod n2)
(* string *)
| Badd, Vstring n1, Vstring n2 -> Vstring (String.cat n1 n2)
(* bool *)
| Beq, _, _ -> Vbool (compare Beq v1 v2)
| Bneq, _, _ -> Vbool (compare Bneq v1 v2)
| Blt, _, _ -> Vbool (compare Blt v1 v2)
| Ble, _, _ -> Vbool (compare Ble v1 v2)
| Bgt, _, _ -> Vbool (compare Bgt v1 v2)
| Bge, _, _ -> Vbool (compare Bge v1 v2)
(*
| Badd, Vlist l1, Vlist l2 ->
assert false (* TODO (question 5) *)
*)
| _ -> error "unsupported operand types"
end
| Eunop (Uneg, e1) ->
Vint ( match expr ctx e1 with
| Vint v -> - v
| _ -> error "unsupported operand type")
(* Boolean *)
| Ebinop (Band, e1, e2) ->
let v1 = expr ctx e1 in
if is_true v1
then expr ctx e2
else v1
| Ebinop (Bor, e1, e2) ->
let v1 = expr ctx e1 in
if is_true v1
then v1
else
expr ctx e2
| Eunop (Unot, e1) ->
Vbool ( match expr ctx e1 with
| Vbool b -> not b
| _ -> error "unsupported operand type in 'not'")
| Eident {id} ->
Hashtbl.find ctx id
(* function call *)
| Ecall ({id="len"}, [e1]) ->
begin match expr ctx e1 with
| Vstring s -> Vint (String.length s)
| Vlist l -> Vint (Array.length l)
| _ -> error "this value has no 'len'" end
| Ecall ({id="list"}, [Ecall ({id="range"}, [e1])]) ->
let n = expr ctx e1 in
Vlist (match n with
| Vint n -> Array.init n (fun i -> Vint i)
| _ -> error "unsupported operand type in 'list'")
| Ecall ({id=f}, el) ->
if not (Hashtbl.mem functions f) then error ("unbound function " ^ f);
let args, body = Hashtbl.find functions f in
if List.length args <> List.length el then error "bad arity";
let ctx' = Hashtbl.create 16 in
List.iter2 (fun {id=x} e -> Hashtbl.add ctx' x (expr ctx e)) args el;
begin try stmt ctx' body; Vnone with Return v -> v end
| Elist el ->
Vlist (Array.of_list (List.map (expr ctx) el))
| Eget (e1, e2) ->
match expr ctx e2 with
| Vint i ->
begin match expr ctx e1 with
| Vlist l ->
if i < 0 || i >= Array.length l then error "index out of bounds"
else l.(i)
| _ -> error "list expected" end
| _ -> error "integer expected"
(* Interpreting a statement
returns nothing but may raise exception `Return` *)
and expr_int ctx e = match expr ctx e with
| Vbool false -> 0
| Vbool true -> 1
| Vint n -> n
| _ -> error "integer expected"
and stmt ctx = function
| Seval e ->
ignore (expr ctx e)
| Sprint e ->
print_value (expr ctx e); printf "@."
| Sblock bl ->
block ctx bl
| Sif (e, s1, s2) ->
if is_true(expr ctx e) then
stmt ctx s1
else
stmt ctx s2
| Sassign ({id}, e1) ->
Hashtbl.replace ctx id (expr ctx e1)
| Sreturn e ->
raise (Return (expr ctx e))
| Sfor ({id=x}, e, s) ->
begin match expr ctx e with
| Vlist l ->
Array.iter (fun v -> Hashtbl.replace ctx x v; stmt ctx s) l
| _ -> error "list expected" end
| Sset (e1, e2, e3) ->
match expr ctx e1 with
| Vlist l ->
let index= expr_int ctx e2 in
l.(index)<- expr ctx e3
| _ -> error "list expected"
(* Interpreting a block (a sequence of statements) *)
and block ctx = function
| [] -> ()
| s :: sl -> stmt ctx s; block ctx sl
(* Interpreting a file
- `dl` is a list of function definitions (see type `def` in ast.ml)
- `s` is a statement (the toplevel code)
*)
let file (dl, s) =
List.iter
(fun (f,args,body) -> Hashtbl.add functions f.id (args, body)) dl;
stmt (Hashtbl.create 16) s
hw3
run.sh
ocaml HW3.ml
dot -Tpdf autom2.dot > autom.pdf && firefox autom.pdf
ocamlopt a.ml lexer.ml && ./a.out
hw3
type ichar = char * int
type regexp =
| Epsilon
| Character of ichar
| Union of regexp * regexp
| Concat of regexp * regexp
| Star of regexp
(*
Exercise 1: Nullity of a regular expression
val null : regexp -> bool
*)
let rec null a =
match a with
| Epsilon ->
true
| Character (c,v) ->
false
| Union (r1,r2) ->
null(r1) || null(r2)
| Concat (r1,r2) ->
null(r1) && null(r2)
| Star r1 ->
true
let () =
let a = Character ('a', 0) in
assert (not (null a));
assert (null (Star a));
assert (null (Concat (Epsilon, Star Epsilon)));
assert (null (Union (Epsilon, a)));
assert (not (null (Concat (a, Star a))))
let () = print_endline "🎉✅ Exercise 1: tests passed successfully!"
(*
Exercise 2: The first and the last
*)
module Cset = Set.Make(struct type t = ichar let compare = Stdlib.compare end)
(*
val first : regexp -> Cset.t
*)
let rec first r =
match r with
| Epsilon -> Cset.empty (* Epsilon has no characters *)
| Character c -> Cset.singleton c (* The character itself is the first *)
| Union (r1, r2) -> Cset.union (first r1) (first r2)
| Concat (r1, r2) -> if null r1 then Cset.union (first r1) (first r2)
else first r1
| Star r1 -> first r1 (* Star can repeat, but first is just the first of the repeated expression *)
(*
val last : regexp -> Cset.t
*)
let rec last r =
match r with
| Epsilon -> Cset.empty (* Epsilon has no characters *)
| Character c -> Cset.singleton c (* The character itself is the first *)
| Union (r1, r2) -> Cset.union (last r1) (last r2)
| Concat (r1, r2) -> if null r2 then Cset.union (last r1) (last r2)
else last r2
| Star r1 -> last r1 (* Star can repeat, but first is just the first of the repeated expression *)
let () =
let ca = ('a', 0) and cb = ('b', 0) in
let a = Character ca and b = Character cb in
let ab = Concat (a, b) in
let eq = Cset.equal in
assert (eq (first a) (Cset.singleton ca));
assert (eq (first ab) (Cset.singleton ca));
assert (eq (first (Star ab)) (Cset.singleton ca));
assert (eq (last b) (Cset.singleton cb));
assert (eq (last ab) (Cset.singleton cb));
assert (Cset.cardinal (first (Union (a, b))) = 2);
assert (Cset.cardinal (first (Concat (Star a, b))) = 2);
assert (Cset.cardinal (last (Concat (a, Star b))) = 2)
let () = print_endline "🎉✅ Exercise 2: tests passed successfully!"
(*
Exercise 3: The follow
*)
let print x =
match x with
| (c,v) -> print_endline (Char.escaped c ^ " " ^ string_of_int v)
let print_set pre x =
(* Cset.iter (fun (c,v) -> print_string (Char.escaped c ^ " " ^ string_of_int v ^ "\n")) x *)
print_endline pre;
Cset.iter (fun (c,v) -> print_string ( pre ^ " " ^ Char.escaped c ^ " " ^ string_of_int v ^ "\n")) x
(* let ()=print_string "\n" *)
(* val follow : ichar -> regexp -> Cset.t *)
let rec follow ic r =
match r with
| Epsilon ->
Cset.empty (* Epsilon has no characters *)
| Character (c,v) ->
Cset.empty
| Union (r1, r2) ->
Cset.union (follow ic r1) (follow ic r2)
| Concat (r1, r2) ->
let x= last(r1) in
if Cset.mem ic x then
Cset.union (Cset.union (follow ic r1 ) (follow ic r2 )) (first r2 )
else
Cset.union (follow ic r1 ) (follow ic r2 )
| Star r1 ->
let x= last(r1) in
if Cset.mem ic x then
Cset.union (follow ic r1 ) (first r1 )
else
follow ic r1
let () =
let ca = ('a', 0) and cb = ('b', 0) in
let a = Character ca and b = Character cb in
let ab = Concat (a, b) in
assert (Cset.equal (follow ca ab) (Cset.singleton cb));
assert (Cset.is_empty (follow cb ab));
let r = Star (Union (a, b)) in
assert (Cset.cardinal (follow ca r) = 2);
assert (Cset.cardinal (follow cb r) = 2);
let r2 = Star (Concat (a, Star b)) in
assert (Cset.cardinal (follow cb r2) = 2);
let r3 = Concat (Star a, b) in
assert (Cset.cardinal (follow ca r3) = 2)
let () = print_endline "🎉✅ Exercise 3: tests passed successfully!"
(* Exercise 4: Construction of the automaton *)
type state = Cset.t (* a state is a set of characters *)
module Cmap = Map.Make(Char) (* dictionary whose keys are characters *)
module Smap = Map.Make(Cset) (* dictionary whose keys are states *)
type autom = {
start : state;
trans : state Cmap.t Smap.t (* state dictionary -> (character dictionary ->state) *)
}
(* cmap[c]=state *)
(* smap[state]=cmap *)
let map1= Cmap.add 'a' Cset.empty Cmap.empty
let map2= Smap.add Cset.empty map1 Smap.empty
(* val next_state : regexp -> Cset.t -> char -> Cset.t *)
(* val next_state : regexp -> state -> char -> state *)
let rec next_state r s c =
(* Combine the first sets of states reachable from s via character c
according to the transitions defined by r. *)
let reachable_states =
Cset.fold (fun (ch, v) acc ->
(* print_endline (Char.escaped ch ^ " " ^ string_of_int v ^ " " ^ Char.escaped c); *)
if ch = c then
(* let ()= print_set "follow" (follow (ch, v) r) in *)
(* let f=(follow (ch, v) r) in *)
Cset.union acc (follow (ch, v) r)
else
acc
) s Cset.empty
in
reachable_states
let eof = ('#', -1)
(* val make_dfa : regexp -> autom *)
let make_dfa (r:regexp) =
let r = Concat (r, Character eof) in
(* let k = Epsilon in *)
(* let r = Concat (r,k ) in *)
let trans = ref Smap.empty in
let rec transitions q =
let find_all_next_state =
Cset.fold (fun (c, v) map ->
let q' = next_state r q c in
Cmap.add c q' map
) q Cmap.empty
in
trans := Smap.add q find_all_next_state !trans;
(* Process the newly added states in transitions map *)
Cmap.iter (fun c q' ->
(* the state that not find yet *)
if not (Smap.mem q' !trans) then
transitions q'
) find_all_next_state;
in
let q0 = first r in
transitions q0;
{ start = q0; trans = !trans }
let fprint_state fmt q =
Cset.iter (fun (c,i) ->
if c = '#' then Format.fprintf fmt "# " else Format.fprintf fmt "%c%i " c i) q
let fprint_transition fmt q c q' =
Format.fprintf fmt "\"%a\" -> \"%a\" [label=\"%c\"];@\n"
fprint_state q
fprint_state q'
c
let fprint_autom fmt a =
Format.fprintf fmt "digraph A {@\n";
Format.fprintf fmt " @[\"%a\" [ shape = \"rect\"];@\n" fprint_state a.start;
Smap.iter
(fun q t -> Cmap.iter (fun c q' -> fprint_transition fmt q c q') t)
a.trans;
Format.fprintf fmt "@]@\n}@."
let save_autom file a =
let ch = open_out file in
Format.fprintf (Format.formatter_of_out_channel ch) "%a" fprint_autom a;
close_out ch
let () = print_endline "🎉✅ Exercise 4: tests passed successfully!"
(* Exercise 5: Word recognition *)
(* val recognize : autom -> string -> bool *)
let recognize (a:autom) (s:string) =
(* let str_with_eof = s ^ "#" in *)
let str_with_eof = s in
let final_state,accpet = String.fold_left (fun (q,accpet) c ->
if Cset.is_empty q then
(* accpet or out of trans *)
(q,accpet)
else
let cmap = Smap.find q a.trans in
if Cmap.mem c cmap then
let q' = Cmap.find c cmap in
(* let () = print_endline (Char.escaped c) in
let () = print_set "final" q' in
let _ =print_endline (string_of_bool( Cset.is_empty q' ))in *)
(q', Cset.mem eof q')
else
(*out of trans *)
(Cset.empty,false)
) (a.start,Cset.mem eof a.start) str_with_eof in
accpet
(* (a|b)*a(a|b) *)
let r = Concat (Star (Union (Character ('a', 1), Character ('b', 1))),
Concat (Character ('a', 2),
Union (Character ('a', 3), Character ('b', 2))))
let a = make_dfa r
let () = save_autom "autom.dot" a
(* positive test *)
let () = assert (recognize a "aa")
let () = assert (recognize a "ab")
let () = assert (recognize a "abababaab")
let () = assert (recognize a "babababab")
let () = assert (recognize a (String.make 1000 'b' ^ "ab"))
(* neg test *)
let () = assert (not (recognize a ""))
let () = assert (not (recognize a "a"))
let () = assert (not (recognize a "b"))
let () = assert (not (recognize a "ba"))
let () = assert (not (recognize a "aba"))
let () = assert (not (recognize a "abababaaba"))
let r = Star (Union (Star (Character ('a', 1)),
Concat (Character ('b', 1),
Concat (Star (Character ('a',2)),
Character ('b', 2)))))
let a = make_dfa r
let () = save_autom "autom2.dot" a
let () = assert (recognize a "")
let () = assert (recognize a "bb")
let () = assert (recognize a "aaa")
let () = assert (recognize a "aaabbaaababaaa")
let () = assert (recognize a "bbbbbbbbbbbbbb")
let () = assert (recognize a "bbbbabbbbabbbabbb")
let () = assert (not (recognize a "b"))
let () = assert (not (recognize a "ba"))
let () = assert (not (recognize a "ab"))
let () = assert (not (recognize a "aaabbaaaaabaaa"))
let () = assert (not (recognize a "bbbbbbbbbbbbb"))
let () = assert (not (recognize a "bbbbabbbbabbbabbbb"))
let () = print_endline "🎉✅ Exercise 5: tests passed successfully!"
(* Exercise 6: Generating a lexical analyzer *)
type buffer = { text: string; mutable current: int; mutable last: int }
let next_char b =
if b.current = String.length b.text then raise End_of_file;
let c = b.text.[b.current] in
b.current <- b.current + 1;
c
type gen_state={
id: int ;
trans:state Cmap.t Smap.t;
}
(* val generate: string -> autom -> unit *)
let generate (filename: string) (a: autom) =
let channel = open_out filename in
try
let state_id = ref Smap.empty in
let count = ref 0 in
(* Write formatted content to the file *)
Printf.fprintf channel "%s" "type buffer = { text: string; mutable current: int; mutable last: int }\n";
Printf.fprintf channel "%s" "let next_char b =
if b.current = String.length b.text then raise End_of_file;
let c = b.text.[b.current] in
b.current <- b.current + 1;
c\n";
let update_state_id (q : state) =
if not (Smap.mem q !state_id) then (
state_id := Smap.add q !count !state_id;
count := !count + 1;
);
Smap.find q !state_id
in
let gen_state = Smap.fold (fun k v s ->
let i=update_state_id k in
(* first state *)
let prefix_string = Format.asprintf (if i = 0 then "let rec state%i b =\n" else "and state%i b =\n") i in
(* accept state *)
let accept = Cset.mem eof k in
(* let prefix_string =if accept then prefix_string ^ " print_endline ((string_of_int b.last)^(string_of_int b.current));\n" else prefix_string in *)
if accept then
let prefix_string =if accept then prefix_string ^ " b.last <- b.current;\n" else prefix_string in
let s'=s^(prefix_string)^"\n"in
s'
else
let prefix_string = prefix_string ^ " let c = next_char b in\n" in
let prefix_string = prefix_string ^ " match c with \n" in
let match_string = Cmap.fold (fun c q s' ->
let q_id = update_state_id q in
let s'' = Format.asprintf " | '%c' -> state%i b\n" c q_id in
s' ^ s''
) v "" in
let match_string = match_string ^ " | _ -> raise (Failure \"undefine key in state\")\n" in
let state_string=prefix_string ^ match_string in
let s'=s^(state_string)^"\n"in
s'
) a.trans "" in
let start_string = Format.asprintf "let start = state%i\n" (Smap.find a.start !state_id)in
let gen_state = gen_state ^ start_string in
Printf.fprintf channel "%s" gen_state;
close_out channel
with e ->
(* Ensure the file is closed if an error occurs *)
close_out_noerr channel;
raise e
(* a*b *)
let r3 = Concat (
Star (Character ('a', 1)),
Character ('b', 1)
)
let a = make_dfa r3
let () = save_autom "autom2.dot" a
let () = generate "a.ml" a
let () = print_endline "🎉✅ Exercise 6: tests passed successfully!"
lexer.ml
(* type buffer = { text: string; mutable current: int; mutable last: int } *)
type buffer = A.buffer
let () =
let str = "abbaaab" in
(* let (b: ref A.buffer) = ref { text = str; current = 0; last = -1 } in *)
let (b: A.buffer) = { text = str; current = 0; last = -1 } in
let flag = ref true in
let start = A.start in
while !flag do
try
let last = if b.last = -1 then 0 else b.last in
let () = start b in
(* print_endline ( "last: "^(string_of_int b.last) ^" current: "^(string_of_int b.current)); *)
if b.last != -1 then
(* print_endline ( (string_of_int last) ^" "^(string_of_int b.last)); *)
let ac_string=String.sub b.text (last) (b.last-last) in
print_endline ("---> "^ac_string)
;
with e ->
print_endline (Printexc.to_string e);
match Printexc.to_string e with
| "Failure \"undefine key in state\"" -> flag := false
| "End_of_file" -> flag := false
| _ -> ()
done
computer-graphics
Deferred Rendering
old way

The old render pipeline used to directly transport the rendered pixel results to the screen, without providing a way to save the rendered image.
Before using Deferred Rendering, we used to calculate the mesh information required for lighting in one shader. This method is efficient when there is a constant number of lights in the scene, as we only need to run one shader for each model to properly apply lighting.
But we have 2 defect
- The number of lights in the shader needs to be constant because the shader has to be compiled at runtime for each frame.
- The same information used to calculate lighting for a mesh (such as mesh normal and mesh color) cannot be shared with another shader, such as a post-processing shader. Therefore, the same information needs to be recalculated in each shader that uses it.
framebuffer

The frame buffer is a hardware implementation in the GPU that can be used as a temporary buffer to store the rendered results. It can also save the results back to the texture memory in the GPU.
With the frame buffer, we can render the information that we will use multiple times and reuse it from the texture memory, rather than recalculating it each time.
deferred lighting
shadow
A shadow is created when one mesh occludes another in the path of a light source. The way to achieve this is to render a depth texture and then render the closest mesh in the path of the light source. This is done repeatedly for each light source, and the resulting images are saved as textures in a framebuffer.
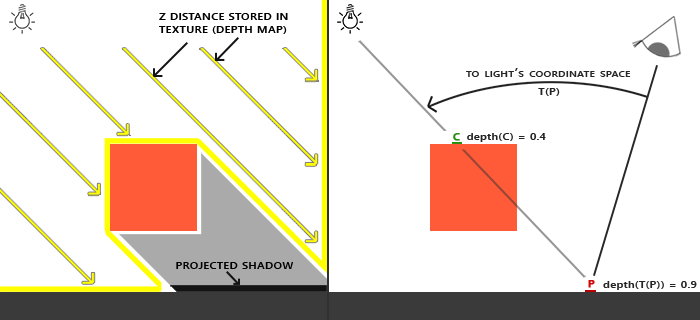
By comparing the depth of a mesh to the closest depth to the light source, we can determine whether the mesh is the closest or not.
shadow projection
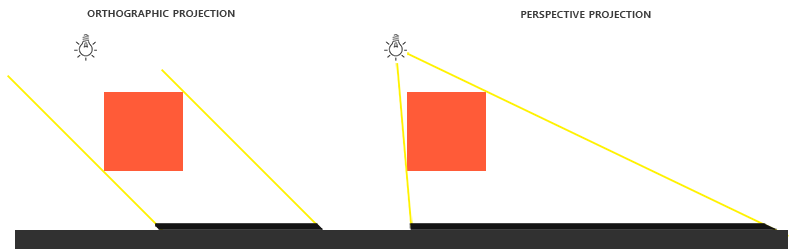
- orthographic: use on direction light like sun.
- prespective: use on point light like flash.
lighting compose
The deferred lighting is based on the G-buffer (which stores information like position and normal on a texture), and calculates the lighting in screen space. Each light is rendered as a separate layer. However, there is a problem with adding lighting layer by layer in the same texture, as it can cause race conditions due to simultaneous reading and writing.

Interestingly, when the VRAM in GPU is fast enough, which means that reading is faster than writing, the race condition may not occur. This is why we were initially confused about this problem, as it did not show up on my computer but did on another computer.
| Lighting Type | Image |
|---|---|
| Point Light |  |
| Point and Direction Light |  |
| Point, Direction, and Ambient Light |  |
postprocess
the postprocess effect on render often relia on the mesh information for example like outliner need a mesh id mask for edge delection.
distance fog from minecraft
 our scene
our scene

use distance to blend with fog color because use the deferred render it is easy to acess depth and position from scene
deferred rendering
:::spoiler images each G-Buffer
| Render Type | Image |
|---|---|
| Albedo |  |
| Normal |  |
| Arm |  |
| Depth |  |
| ID |  |
| Lighting |  |
:::
computer networking
delay
circuit switching(FDM,TDM)
Frequency Division Multiplexing (FDM)
optical, electromagnetic frequencies divided into (narrow) frequency bands = each call allocated its own band, can transmit at max rate of that narrow band
Time Division Multiplexing (TDM)
time divided into slots = each call allocated periodic slot(s), can transmit at maximum rate of (wider) frequency band, but only during its time slot(s)
applicaion layer
http
http/1.0
- TCP connection opened
- at most one object sent over TCP connection
- Non-persistent HTTP。
http/1.1
- pipelined GETs over single TCP connection
- persistent HTTP。
http/2
- multiple, pipelined GETs over single TCP connection
- push unrequested objects to clien
http/3
This is an advanced transport protocol that operates on top of UDP. QUIC incorporates features like reduced connection and transport latency, multiplexing without head-of-line blocking, and improved congestion control. It integrates encryption by default, providing a secure connection setup with a single round-trip time (RTT).
persistent http
- keep connetion of TCP
- half time of tramit
email SMTP POP3 IMAP
SMTP
mail server send to mail server
POP3
muil-user download email
IMAP
will delete email that user download
| http | smtp | |
|---|---|---|
| pull | push | |
| encode | ASCII | ASCII |
| multiple obj | encapsulated in its own response message | multiple objects sent in multipart message |
DNS
- hostname to IP address translation
- host aliasing
- mail server aliasing
- take but 2 RTT(one for make connection one for return IP info) to get send IP back
socket
use this four tuple to identified TCP packet
(source IP, source port, destination IP, destination port)
UDP
- no handshaking before sending data
- sender explicitly attaches IP destination address and port # to each packet
- receiver extracts sender IP address and port# from received packe
- transmitted data may be lost or received out-of-order
TCP
- reliable, byte stream-oriented
- server process must first be running
- server must have created socket (door) that welcomes client’s contact
- TCP 3-way handshake
Multimedia video:
- DASH: Dynamic, Adaptive Streaming over HTT
- CBR: (constant bit rate): video encoding rate fixed
- VBR: (variable bit rate): video encoding rate changes as amount of spatial, temporal coding changes
principles of reliable data transfer
- finite state machines (FSM)
- Sequence numbers:
- byte stream “number” of first byte in segment’s data
- Acknowledgements:
- seq # of next byte expectet from other side
- cumulative ACK
Go Back N
the all the packet that behind is overtime or NAK
Selective repeat
only resend the packet overtime or NAK
stop and wait
rdt(reliable data transfer)
rdt 1.0
- rely on channel perfectly reliable
rdt 2.0
- checksum to detect bit errors
- acknowledgements (ACKs): receiver explicitly tells sender that pkt received OK
- negative acknowledgements (NAKs): receiver explicitly tells sender that pkt had errors
- stop and wait: sender sends one packet, then waits for receiver response
rdt 2.1
在每份封包加入序號(sequence number) 來編號,因此接收端可以藉由序號判斷現在收到的封包是不是重複的,若重複則在回傳一次ACK回去,而這裡的序號用1位元就夠了(0和1交替)。
-
sender
-
receiver
rdt 2.2
rdt2.2不再使用NAK,而是在ACK加入序號的訊息,所以在接收端的make_pkt()加入參數ACK,0或ACK,1,而在傳送端則是要檢查所收到ACK的序號。
rdt 3.0
- add timer .If sender not receive ACK then resend
TCP flow control
receiver controls sender, so sender won’t overflow receiver’s buffer by transmitting too much, too fast
window buffer size
if the receiver window buffer is fill then sender should stop sending until receiver window buffer is free again
SampleRTT
- measured time from segment transmission until ACK receipt
- ignore retransmissions
- SampleRTT will vary, want estimated RTT “smoother” average several recent measurements, not just current SampleRTT
TCP RTT(round trip time), timeout
- use EWMA(exponential weighted moving average)
- influence of past sample decreases exponentially fast
- typical value: = 0.125
TCP congestion control AIMD(Additive Increase Multiplicative Decrease)
- send cwnd bytes,wait RTT for ACKS, then send more bytes
slow start
increase rate exponentially until first loss event
- initially cwnd = 1 MSS
- double cwnd every RTT
- done by incrementing cwnd for every ACK received
CUBIC (briefly)
use the cubic function(三次函數) to predict bottlenck
3 duplicate ack
if recevie 3 ACK of same packet then see as reach bottlenck
congestion avoidance AIMD(Additive Increase Multiplicative Decrease)
Network Layer:
- functions
- network-layer functions:
- forwarding: move packets from a router’s input link to appropriate router output link
- routing: determine route taken by packets from source to destination
- routing algorithms
- analogy: taking a trip
- forwarding: process of getting through single interchange
- routing: process of planning trip from source to destination
- network-layer functions:
- data plane and control plane
- Data plane:
- local, per-router function
- determines how datagram arriving on router input port is forwarded to router output port
- forwarding: move packets from router’s input to appropriate router output
- Control plane:
- network-wide logic
- routing: determine route taken by packets from source to destination
- determines how datagram is routed among routers along end- end path from source host to destination host
- two control-plane approaches:
- traditional routing algorithms: implemented in routers
- software-defined networking Software-Defined Networking((SDN): implemented in (remote) servers
- Data plane:
Network layer:Data Plane(CH4)
Router
- input port queuing: if datagrams arrive faster than forwarding rate into switch fabri
- destination-based forwarding: forward based only on destination IP address (traditional)
- generalized forwarding: forward based on any set of header field values
Input port functions
Destination-based forwarding(Longest prefix matching)
- when looking for forwarding table entry for given destination address, use longest address prefix that matches destination address.
Switching fabrics
- transfer packet
- from input link to appropriate output link
- switching rate:
- rate at which packets can be transfer from
Input Output queuing
- input
- If switch fabric slower than input ports combined -> queueing may occur at input queues
- queueing delay and loss due to input buffer overflow!
- Head-of-the-Line (HOL) blocking: queued datagram at front of queue prevents others in queue from moving forward
- If switch fabric slower than input ports combined -> queueing may occur at input queues
- output
- Buffering
- drop policy: which datagrams to drop if no free buffers?
- Datagrams can be lost due to congestion, lack of buffers
- Priority scheduling – who gets best performance, network neutrality
- Buffering
buffer management
- drop: which packet to add,drop when buffers are full
- tail drop: drop arriving packet
- priority: drop/remove on priority basis
- marking: which packet to mark to signal congestion(ECN,RED)
packet scheduling
-
FCFS(first come, first served)
-
priority
- priority queue
-
RR(round robin)
- arriving traffic classified, queued by class(any header fields can be used for classification)
- server cyclically, repeatedly scans class queues, sending one complete packet from each class (if available) in turn
-
WFQ(Weighted Fair Queuing)
- round robin but each class, , has weight, , and gets weighted amount of service in each cycle
IP (Internet Protoco)
IP Datagram
IP address
- IP address: 32-bit identifier associated with each host or router interface
- interface: connection between host/router and physical link
- router’s typically have multiple interfaces
- host typically has one or two interfaces (e.g., wired Ethernet, wireless 802.11)
Subnets
- in same subnet if:
- device interfaces that can physically reach each other without passing through an intervening router
CIDR(Classless InterDomain Routing)
address format: a.b.c.d/x, where x is # bits in subnet portion of address
DHCP
host dynamically obtains IP address from network server when it “joins” network
- host broadcasts DHCP discover msg [optional]
- DHCP server responds with DHCP offer msg [optional]
- host requests IP address: DHCP request msg
- DHCP server sends address: DHCP ack msg
NAT(Network Address Translation)
- NAT has been controversial:
- routers “should” only process up to layer 3
- address “shortage” should be solved by IPv6
- violates end-to-end argument (port # manipulation by network-layer device)
- NAT traversal: what if client wants to connect to server behind NAT?
- but NAT is here to stay:
- extensively used in home and institutional nets, 4G/5G cellular net
IP6
tunneling:Transition from IPv4 to IPv6
IPv6 datagram carried as payload in IPv4 datagram among IPv4 routers (“packet within a packet”)
Generalized forwarding(flow table)
flow table entries
- match+action: abstraction unifies different kinds of devices
| Device | Match | Action |
|---|---|---|
| Router | Longest Destination IP Prefix | Forward out a link |
| Switch | Destination MAC Address | Forward or flood |
| Firewall | IP Addresses and Port Numbers | Permit or deny |
| NAT | IP Address and Port | Rewrite address and port |
middleboxes
Network layer:Control Plane(CH5)
- structuring network control plane:
- per-router control (traditional)
- logically centralized control (software defined networking)
Routing protocols
Dijkstra’s link-state routing algorithm
- centralized: network topology, link costs known to all node
- iterative: after k iterations, know least cost path to k destinations
Distance vector algorithm(Bellman-Ford)
- from time-to-time, each node sends its own distance vector estimate to neighbors
- under natural conditions, the estimate Dx(y) converge to the actual least cost dx(y)
- when x receives new DV estimate from any neighbor, it updates its own DV using B-F equation
- link cost changes:
- node detects local link cost change
- updates routing info, recalculates local DV
- if DV changes, notify neighbors
Intra-AS routing
- RIP: Routing Information Protocol [RFC 1723]
- classic DV: DVs exchanged every 30 secs
- no longer widely used
- EIGRP: Enhanced Interior Gateway Routing Protocol
- DV based
- formerly Cisco-proprietary for decades (became open in 2013 [RFC 7868])
- OSPF: Open Shortest Path First [RFC 2328]
- classic link-state
- each router floods OSPF link-state advertisements (directly over IP rather than using TCP/UDP) to all other routers in entire AS
- multiple link costs metrics possible: bandwidth, delay
- each router has full topology, uses Dijkstra’s algorithm to compute forwarding table
- security: all OSPF messages authenticated (to prevent malicious intrusion)
- classic link-state
Inter-AS routing
- BGP (Border Gateway Protocol)inter-domain routing protocol:
- eBGP: obtain subnet reachability information from neighboring ASes
- iBGP: propagate reachability information to all AS-internal routers
Why different Intra-AS, Inter-AS routing ?
| Criteria | Intra-AS | Inter-AS |
|---|---|---|
| Policy | Single admin, no policy decisions needed | Admin wants control over how traffic is routed, and who routes through its network |
| Scale | Hierarchical routing saves table size, reduced update traffic | |
| Performance | Can focus on performance | Policy dominates over performance |
ICMP: internet control message protocol
- used by hosts and routers to communicate network-level information
- error reporting: unreachable host, network, port, protocol
- echo request/reply (used by ping)
- network-layer “above: IP:
- ICMP messages carried in IP datagrams
- ICMP message: type, code plus first 8 bytes of IP datagram causing error
Link layer and LAN(CH6)
- flow control:
- pacing between adjacent sending and receiving nodes
- error detection:
- errors caused by signal attenuation, noise.
- receiver detects errors, signals retransmission, or drops frame
- error correction:
- receiver identifies and corrects bit error(s) without retransmission
- half-duplex and full-duplex:
- with half duplex, nodes at both ends of link can transmit, but not at sam
error detection, correction
- Internet checksum
- Parity checking
- Cyclic Redundancy Check (CRC)
Parity checking
Cyclic Redundancy Check (CRC)
MAC protocol(multiple access)
- channel partitioning
- time division
- frequency division
- random access MAC protocol
- ALOHA, slotted ALOHA
- CSMA
- CSMA/CD: ethernet
- CSMA/CA: 802.11
- takeing turns
- polling(token passing)
- bluetooth,token ring
slotted ALOHA
- time divided into equal size slots (time to transmit 1 frame)
- nodes are synchronized
- if collision: node retransmits frame in each subsequent slot with probability until success
- max efficiency = = 0.37
Pure ALOHA
CSMA
- CSMA:
- if channel sensed idle: transmit entire frame • if channel sensed busy: defer transmission
- CSMA/CD(Collision Detection):
- collision detection easy in wired, difficult with wireless
- if collisions detected within short then send
abort,jam signal - After aborting, NIC enters binary (exponential) backoff:
- after mth collision, NIC chooses K at random from {0,1,2, …, 2m-1}. NIC waits bit times
- more collisions: longer backoff interval
LAN
ARP: address resolution protocol
determine interface’s MAC address by its IP address
- ARP table: each IP node (host, router) on LAN has table
- IP/MAC address mappings for some LAN nodes: < IP address; MAC address; TTL>
- TTL (Time To Live): time after which address mapping will be forgotten (typically 20 min)
- destination MAC address =
FF-FF-FF-FF-FF-FF
switch
switch table
computer networking
delay
circuit switching(FDM,TDM)
Frequency Division Multiplexing (FDM)
optical, electromagnetic frequencies divided into (narrow) frequency bands = each call allocated its own band, can transmit at max rate of that narrow band
Time Division Multiplexing (TDM)
time divided into slots = each call allocated periodic slot(s), can transmit at maximum rate of (wider) frequency band, but only during its time slot(s)
applicaion layer
http
http/1.0
- TCP connection opened
- at most one object sent over TCP connection
- Non-persistent HTTP。
http/1.1
- pipelined GETs over single TCP connection
- persistent HTTP。
http/2
- multiple, pipelined GETs over single TCP connection
- push unrequested objects to clien
http/3
This is an advanced transport protocol that operates on top of UDP. QUIC incorporates features like reduced connection and transport latency, multiplexing without head-of-line blocking, and improved congestion control. It integrates encryption by default, providing a secure connection setup with a single round-trip time (RTT).
persistent http
- keep connetion of TCP
- half time of tramit
email SMTP POP3 IMAP
SMTP
mail server send to mail server
POP3
muil-user download email
IMAP
will delete email that user download
| http | smtp | |
|---|---|---|
| pull | push | |
| encode | ASCII | ASCII |
| multiple obj | encapsulated in its own response message | multiple objects sent in multipart message |
DNS
- hostname to IP address translation
- host aliasing
- mail server aliasing
- take but 2 RTT(one for make connection one for return IP info) to get send IP back
socket
use this four tuple to identified TCP packet
(source IP, source port, destination IP, destination port)
UDP
- no handshaking before sending data
- sender explicitly attaches IP destination address and port # to each packet
- receiver extracts sender IP address and port# from received packe
- transmitted data may be lost or received out-of-order
TCP
- reliable, byte stream-oriented
- server process must first be running
- server must have created socket (door) that welcomes client’s contact
- TCP 3-way handshake
Multimedia video:
- DASH: Dynamic, Adaptive Streaming over HTT
- CBR: (constant bit rate): video encoding rate fixed
- VBR: (variable bit rate): video encoding rate changes as amount of spatial, temporal coding changes
principles of reliable data transfer
- finite state machines (FSM)
- Sequence numbers:
- byte stream “number” of first byte in segment’s data
- Acknowledgements:
- seq # of next byte expectet from other side
- cumulative ACK
Go Back N
the all the packet that behind is overtime or NAK
Selective repeat
only resend the packet overtime or NAK
stop and wait
rdt(reliable data transfer)
rdt 1.0
- rely on channel perfectly reliable
rdt 2.0
- checksum to detect bit errors
- acknowledgements (ACKs): receiver explicitly tells sender that pkt received OK
- negative acknowledgements (NAKs): receiver explicitly tells sender that pkt had errors
- stop and wait: sender sends one packet, then waits for receiver response
rdt 2.1
在每份封包加入序號(sequence number) 來編號,因此接收端可以藉由序號判斷現在收到的封包是不是重複的,若重複則在回傳一次ACK回去,而這裡的序號用1位元就夠了(0和1交替)。
-
sender
-
receiver
rdt 2.2
rdt2.2不再使用NAK,而是在ACK加入序號的訊息,所以在接收端的make_pkt()加入參數ACK,0或ACK,1,而在傳送端則是要檢查所收到ACK的序號。
rdt 3.0
- add timer .If sender not receive ACK then resend
TCP flow control
receiver controls sender, so sender won’t overflow receiver’s buffer by transmitting too much, too fast
window buffer size
if the receiver window buffer is fill then sender should stop sending until receiver window buffer is free again
SampleRTT
- measured time from segment transmission until ACK receipt
- ignore retransmissions
- SampleRTT will vary, want estimated RTT “smoother” average several recent measurements, not just current SampleRTT
TCP RTT(round trip time), timeout
- use EWMA(exponential weighted moving average)
- influence of past sample decreases exponentially fast
- typical value: = 0.125
TCP congestion control AIMD(Additive Increase Multiplicative Decrease)
- send cwnd bytes,wait RTT for ACKS, then send more bytes
slow start
increase rate exponentially until first loss event
- initially cwnd = 1 MSS
- double cwnd every RTT
- done by incrementing cwnd for every ACK received
CUBIC (briefly)
use the cubic function(三次函數) to predict bottlenck
3 duplicate ack
if recevie 3 ACK of same packet then see as reach bottlenck
congestion avoidance AIMD(Additive Increase Multiplicative Decrease)
Network Layer:
- functions
- network-layer functions:
- forwarding: move packets from a router’s input link to appropriate router output link
- routing: determine route taken by packets from source to destination
- routing algorithms
- analogy: taking a trip
- forwarding: process of getting through single interchange
- routing: process of planning trip from source to destination
- network-layer functions:
- data plane and control plane
- Data plane:
- local, per-router function
- determines how datagram arriving on router input port is forwarded to router output port
- forwarding: move packets from router’s input to appropriate router output
- Control plane:
- network-wide logic
- routing: determine route taken by packets from source to destination
- determines how datagram is routed among routers along end- end path from source host to destination host
- two control-plane approaches:
- traditional routing algorithms: implemented in routers
- software-defined networking Software-Defined Networking((SDN): implemented in (remote) servers
- Data plane:
Network layer:Data Plane(CH4)
Router
- input port queuing: if datagrams arrive faster than forwarding rate into switch fabri
- destination-based forwarding: forward based only on destination IP address (traditional)
- generalized forwarding: forward based on any set of header field values
Input port functions
Destination-based forwarding(Longest prefix matching)
- when looking for forwarding table entry for given destination address, use longest address prefix that matches destination address.
Switching fabrics
- transfer packet
- from input link to appropriate output link
- switching rate:
- rate at which packets can be transfer from
Input Output queuing
- input
- If switch fabric slower than input ports combined -> queueing may occur at input queues
- queueing delay and loss due to input buffer overflow!
- Head-of-the-Line (HOL) blocking: queued datagram at front of queue prevents others in queue from moving forward
- If switch fabric slower than input ports combined -> queueing may occur at input queues
- output
- Buffering
- drop policy: which datagrams to drop if no free buffers?
- Datagrams can be lost due to congestion, lack of buffers
- Priority scheduling – who gets best performance, network neutrality
- Buffering
buffer management
- drop: which packet to add,drop when buffers are full
- tail drop: drop arriving packet
- priority: drop/remove on priority basis
- marking: which packet to mark to signal congestion(ECN,RED)
packet scheduling
-
FCFS(first come, first served)
-
priority
- priority queue
-
RR(round robin)
- arriving traffic classified, queued by class(any header fields can be used for classification)
- server cyclically, repeatedly scans class queues, sending one complete packet from each class (if available) in turn
-
WFQ(Weighted Fair Queuing)
- round robin but each class, , has weight, , and gets weighted amount of service in each cycle
IP (Internet Protoco)
IP Datagram
IP address
- IP address: 32-bit identifier associated with each host or router interface
- interface: connection between host/router and physical link
- router’s typically have multiple interfaces
- host typically has one or two interfaces (e.g., wired Ethernet, wireless 802.11)
Subnets
- in same subnet if:
- device interfaces that can physically reach each other without passing through an intervening router
CIDR(Classless InterDomain Routing)
address format: a.b.c.d/x, where x is # bits in subnet portion of address
DHCP
host dynamically obtains IP address from network server when it “joins” network
- host broadcasts DHCP discover msg [optional]
- DHCP server responds with DHCP offer msg [optional]
- host requests IP address: DHCP request msg
- DHCP server sends address: DHCP ack msg
NAT(Network Address Translation)
- NAT has been controversial:
- routers “should” only process up to layer 3
- address “shortage” should be solved by IPv6
- violates end-to-end argument (port # manipulation by network-layer device)
- NAT traversal: what if client wants to connect to server behind NAT?
- but NAT is here to stay:
- extensively used in home and institutional nets, 4G/5G cellular net
IP6
tunneling:Transition from IPv4 to IPv6
IPv6 datagram carried as payload in IPv4 datagram among IPv4 routers (“packet within a packet”)
Generalized forwarding(flow table)
flow table entries
- match+action: abstraction unifies different kinds of devices
| Device | Match | Action |
|---|---|---|
| Router | Longest Destination IP Prefix | Forward out a link |
| Switch | Destination MAC Address | Forward or flood |
| Firewall | IP Addresses and Port Numbers | Permit or deny |
| NAT | IP Address and Port | Rewrite address and port |
middleboxes
Network layer:Control Plane(CH5)
- structuring network control plane:
- per-router control (traditional)
- logically centralized control (software defined networking)
Routing protocols
Dijkstra’s link-state routing algorithm
- centralized: network topology, link costs known to all node
- iterative: after k iterations, know least cost path to k destinations
Distance vector algorithm(Bellman-Ford)
- from time-to-time, each node sends its own distance vector estimate to neighbors
- under natural conditions, the estimate Dx(y) converge to the actual least cost dx(y)
- when x receives new DV estimate from any neighbor, it updates its own DV using B-F equation
- link cost changes:
- node detects local link cost change
- updates routing info, recalculates local DV
- if DV changes, notify neighbors
Intra-AS routing
- RIP: Routing Information Protocol [RFC 1723]
- classic DV: DVs exchanged every 30 secs
- no longer widely used
- EIGRP: Enhanced Interior Gateway Routing Protocol
- DV based
- formerly Cisco-proprietary for decades (became open in 2013 [RFC 7868])
- OSPF: Open Shortest Path First [RFC 2328]
- classic link-state
- each router floods OSPF link-state advertisements (directly over IP rather than using TCP/UDP) to all other routers in entire AS
- multiple link costs metrics possible: bandwidth, delay
- each router has full topology, uses Dijkstra’s algorithm to compute forwarding table
- security: all OSPF messages authenticated (to prevent malicious intrusion)
- classic link-state
Inter-AS routing
- BGP (Border Gateway Protocol)inter-domain routing protocol:
- eBGP: obtain subnet reachability information from neighboring ASes
- iBGP: propagate reachability information to all AS-internal routers
Why different Intra-AS, Inter-AS routing ?
| Criteria | Intra-AS | Inter-AS |
|---|---|---|
| Policy | Single admin, no policy decisions needed | Admin wants control over how traffic is routed, and who routes through its network |
| Scale | Hierarchical routing saves table size, reduced update traffic | |
| Performance | Can focus on performance | Policy dominates over performance |
ICMP: internet control message protocol
- used by hosts and routers to communicate network-level information
- error reporting: unreachable host, network, port, protocol
- echo request/reply (used by ping)
- network-layer “above: IP:
- ICMP messages carried in IP datagrams
- ICMP message: type, code plus first 8 bytes of IP datagram causing error
Link layer and LAN(CH6)
- flow control:
- pacing between adjacent sending and receiving nodes
- error detection:
- errors caused by signal attenuation, noise.
- receiver detects errors, signals retransmission, or drops frame
- error correction:
- receiver identifies and corrects bit error(s) without retransmission
- half-duplex and full-duplex:
- with half duplex, nodes at both ends of link can transmit, but not at sam
error detection, correction
- Internet checksum
- Parity checking
- Cyclic Redundancy Check (CRC)
Parity checking
Cyclic Redundancy Check (CRC)
MAC protocol(multiple access)
- channel partitioning
- time division
- frequency division
- random access MAC protocol
- ALOHA, slotted ALOHA
- CSMA
- CSMA/CD: ethernet
- CSMA/CA: 802.11
- takeing turns
- polling(token passing)
- bluetooth,token ring
slotted ALOHA
- time divided into equal size slots (time to transmit 1 frame)
- nodes are synchronized
- if collision: node retransmits frame in each subsequent slot with probability until success
- max efficiency = = 0.37
Pure ALOHA
CSMA
- CSMA:
- if channel sensed idle: transmit entire frame • if channel sensed busy: defer transmission
- CSMA/CD(Collision Detection):
- collision detection easy in wired, difficult with wireless
- if collisions detected within short then send
abort,jam signal - After aborting, NIC enters binary (exponential) backoff:
- after mth collision, NIC chooses K at random from {0,1,2, …, 2m-1}. NIC waits bit times
- more collisions: longer backoff interval
LAN
ARP: address resolution protocol
determine interface’s MAC address by its IP address
- ARP table: each IP node (host, router) on LAN has table
- IP/MAC address mappings for some LAN nodes: < IP address; MAC address; TTL>
- TTL (Time To Live): time after which address mapping will be forgotten (typically 20 min)
- destination MAC address =
FF-FF-FF-FF-FF-FF
switch
switch table
hw1
2023 computer-networking HW1.pdf
1.
Determine the bottleneck link, which is the link with the lowest throughput. In this case, the bottleneck link is the first hop with a throughput of 500 kbps.
1.b Repeat 1.a, but now with R3 reduced to 200 Kbps.
The bottleneck link is the first hop with a throughput of 200 kbps.
2.
2.a
2.b
2.c
2.d
3.
4.
5.
Physical Layer:
rincipal responsibilities: Hardware layer, such as cables, connectors, and network interface cards.
Link Layer:
rincipal responsibilities: link two directly connected nodes, and the protocols that they use to communicate.
Network Layer:
rincipal responsibilities: provide the functional and procedural means of transferring variable length data sequences from a source to a destination via one or more networks, while maintaining the quality of service functions.
Transport Layer:
rincipal responsibilities: transport data between two hosts, such as connection-oriented communication and connectionless communication.
Application Layer:
rincipal responsibilities: let application programs that use the network, such as web browsers, email clients, remote file access, etc.
hw2
2023 computer-networking HW2.pdf
1.
use UDP because it is faster then TCP
2.
When a user requests an object, the cache checks if it has a copy of the object. If it does, the cache returns the object to the user without having to retrieve it from the original server
3.
The applications of HTTP, SMTP, and POP3 require more reliability than throughput, so they use TCP.
4.
total time=
This is because each DNS server visited create an RTT, and once the IP address is obtained, an additional RTT is incurred to establish a connection with the server containing the object. The total time elapsed is equal to the sum of all these RTTs
5.a
5.b
5.c
hw4
2023 computer-networking HW4.pdf
1.
Because NAT converts the IP and port before sending or receiving requests from another user or server, it makes it impossible to know the IP of the client.
by using this can make P2P connection network with NAT
- Port Forwarding
- UPnP (Universal Plug and Play)
2.
- Subnets1: 223.3.16.0/25
- Subnets2: 223.3.16.128/26
- Subnets3: 223.3.16.192/26
3.
- Private IP are internal IP for internal network that not should not expose on public network
- No
- If private information is exposed on a public network, hackers may gain access to the private network.
4.
a:Insert IP6 packet as payload in IP4 protocols
b:No ,The data link layer have to communication with physical layer
5.
- the match plus action is the core mechanism of router and switch do thing eff
-
- match :
- compares the destination IP address to the entries in its routing table.
- action :
- forward the packet to the determined
- match :
-
- fields can match :
- Source/Destination IP Address
- Protocol Type
- action :
- Forwarding
- Quality of Service (QoS)
- fields can match :
hw5
2023 computer-networking HW5.pdf
1.
- False.
- Router sends its link information, it is not limited to only those nodes directly attached as neighbors. OSPF routers use a process called “flooding” to share routing information throughout the entire OSPF domain.
2.
- No
- based on reachability information and policy router may not be shortest path
3.
UDP:
- stateless
- faster then TCP
4.
| iter | visited | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| 0 | {} | 0 | |||||
| 1 | {1} | 0 | 1 | 5 | 4 | ||
| 2 | {1,2} | 0 | 1 | 4 | 4 | 2 | |
| 3 | {1,2,5} | 0 | 1 | 3 | 3 | 2 | 6 |
| 4 | {1,2,5,3} | 0 | 1 | 3 | 3 | 2 | 5 |
| 5 | {1,2,5,3,4} | 0 | 1 | 3 | 3 | 2 | 5 |
| 6 | {1,2,5,3,4,6} | 0 | 1 | 3 | 3 | 2 | 5 |
5.
| x | y | w | u | |
|---|---|---|---|---|
| x | 0 | 4 | 2 | 7 |
| y | 4 | 0 | 2 | 6 |
| w | 2 | 2 | 0 | 5 |
| u | 7 | 6 | 5 | 0 |
a.
| x | |
|---|---|
| y | 4 |
| w | 2 |
| u | 7 |
b.
When the function c(x,w) changes, node x will need to recompute the distances to its neighbors. Subsequently, it must send these recalculated distances back to neighbors and receive new distances from neighbors. Then x may have new minimum-cost path.
hw6
2023 computer-networking HW6.pdf
1.
No.
- reliable delivery: ensures that content or resources hosted on websites can be reliably accessed by users
- TCP: lower level, providing a reliable communication channel between two devices on the Internet.
2.
- Broadcasting the ARP query ensures that the request reaches all devices on the network.
- This targeted delivery is more efficient than broadcasting, as it minimizes unnecessary traffic on the network.
3.
4.
5.
5.1
5.2
CSG (Constructive Solid Geometry) note
tags: 3D js
CSG is a methodology for constructing geometries by mesh, using algorithms capable of performing boolean operations like union or difference (A-B), among others.
vector
values
x,y,z for a point or normal
clone
return new same vector
negated
return new same negated
plus(a)
return new vector add a vector
minus(a)
this-a
times(a)
乘a
divideBy(a)
除a
dot(a)
內積
return x*a.x+y*a.y+z*a.zlerp(a,t)
t通常小於1 用來表示this 到a 之間的某個數
this-(this-a)*tlen
unit
單位為1的向量
cross
降階值
[[x ,y ,z ], [a.x ,a.y ,a.z ]]
vertex
value
- pos( vector)
- noraml (vector)
clone
flip
修改normal 方向
interpolate(a,t)
用lerp的方式產生一個介於this 與a 之間的pos and normal並用 t控制落點
plane
value
- normal 面的髮線
- w
- epsilon 可接受誤差值
clone
flip
change the side of the normal
formpoints(a,b,c)
create plane by 3 point vector and w is plane dot with fisrt verctor(position)
splitPolygon(polygon, coplanarFront, coplanarBack, front, back)
以這個面為基準將多個面區分為語法線面相同的front 或back 如果有交集則切割面
polygon
valuemagnitude
- vertices(lot of vertex)
- shared
- plane
- EPSILON(對於點是否在面上的容忍值)
clone
flip
- flip vertex
- flip plane
node
bsp:binary space partitioning tree
利用每個面的髮線區切割空間,如果空間在髮線的背面則視為true(或是包含)
value
- plane
- front=node
- back=node
- polygons=[]
clone
invert
- flip polygons
- flip plane
- flip back and front
- and change back to front 、 change front to back
clip Polygons
clipTo(bsp)
bsp:binary space partitioning tree
a和b的 bsp tree 合併=a-b的截面
+-------+ +-------+ | | | | | A | | | | +--+----+ = | + +----+--+ | +----+ | B | | | +-------+allPolygons
return combon all polygon from back and front to one array
Boolean operations
union
a.clipTo(b); b.clipTo(a); b.invert(); b.clipTo(a); b.invert(); a.build(b.allPolygons());my way
a.clipTo(b); b.clipTo(a); a.build(b.allPolygons());subtract
a.invert(); a.clipTo(b); b.clipTo(a); b.invert(); b.clipTo(a); b.invert(); a.build(b.allPolygons()); a.invert();
my way
a.invert(); a.clipTo(b); b.invert(); b.clipTo(a); a.invert(); a.build(b.allPolygons());intersect
a.invert(); b.clipTo(a); b.invert(); a.clipTo(b); b.clipTo(a); a.build(b.allPolygons()); a.invert();
another way to intersect
a.invert(); b.clipTo(a); b.invert(); a.clipTo(b); a.build(b.allPolygons()); a.invert();
links
- [other way](http: //groups.csail.mit.edu/graphics/classes/6.837/F98/talecture/)
- [paper link](https: //static1.squarespace.com/static/51bb9790e4b0510af19ea9c4/t/51bf7c34e4b0a897bf550945/1371503668974/CSG_report.pdf)
- github
data science
5v
- volume
- variety
- value
- velocity
- veracity
data processing chain
- data
- database
- data store
- data ming
- data value
data warehouse
- subject oriented
- integrate
- non-volatile
- time variant
data warehouse type
- 星形
- 雪花
- 實例星座
data type
| name | exmple |
|---|---|
| nominal data , unordered collection,明目 | dog cat name |
| ordinal data , ordered data ,次序 | level |
| interval data , equal intervals,(not Ture zero)(相除 不可代表比值),區間 | 溫度 |
| ratio data , fraction data,比值 | float |
| BLOB(binary large objects) | image sound file |
Quantile
Q1:small 0%~25%
Q2:small 25%~50%
Q3:small 50%~75%
Q4:small 75%~100%(the biggest)
interQuartile range:Q3-Q1
confusion matrix
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive (True) | TP | FN |
| Actual Negative (False) | FP | TN |
ROC curve
correlations
linear regression
similar function
| h1 | h2 | h3 | h4 | |
|---|---|---|---|---|
| a | 1 | _ | _ | 0.5 |
| b | 0.5 | _ | 0.3 | _ |
| c | _ | 0.7 | _ | 0.4 |
jaccard similarity
cosine similarity
peason correlation coeffiecient
Feature Selection Methods
- Filter methods
- Wrapper methods
- Embedded methods
Classification
Decision Tree
entropy(熵)
Information Gain(IG)
if then entropy is geting less then it is good divide point
gini index(Impurity)
random forest(Bootstrap Aggregation for decision tree)
use mutilple random Decision Tree to vote asnwer
naive bayes
zero conditional(when probability is zero)
t :possible condition number
n :case number
c :possble c
m :virtual sample
Bayesian Network
Bayesian networks are directed and acyclic, whereas Markov networks are undirected and could be cyclic.
SVM(Support Vector Machines)
linear separable SVM
linear inseparable SVM
map data to higher dimension
KNN( K Nearest Neighbor)
- KNN 的演算法步驟如下:
- KNN 中的 K 代表找出距離你最近的 K 筆資料進行分類。
- 假設 K 是 3,代表找出前三筆相近的資料。
- 當這 K 筆資料被選出後,就以投票的方式統計哪一種類的資料量最多,然後就被分到哪一個類別。
Linear Classifiers
Logistic Regression
Gradient Descent
Coordinate Descent
Coordinate descent updates one parameter at a time, while gradient descent attempts to update all parameters at once
Improve Classification Accuracy
Bagging:Bootstrap aggregating
給定一個大小為 n 的訓練集 D,Bagging算法從中均勻、有放回地(即使用自助抽樣法)選出 m個大小為 的子集 ,作為新的訓練集。在這 m 個訓練集上使用分類、回歸等算法,則可得到 m 個模型,在透過取平均值、取多數票等方法,即可得到Bagging的結果。
Boosting
- A series of k classifiers are iteratively learned
- After a classifier Mi is learned, set the subsequent classifier, Mi+1, to pay more
- attention to the training tuples that were misclassified by Mi
- The final M* combines the votes of each individual classifier, where the weight of each classifier’s vote is a function of its accuracy
Imbalanced Data Sets
- Oversampling: Oversample the minority class.
- Under-sampling: Randomly eliminate tuples from majority class
- Synthesizing: Synthesize new minority classes
- Threshold-moving
- Move the decision threshold, t, so that the rare class tuples are easier to classify, and hence, less chance of costly false negative errors
MLP(ANN)
- 人工神经元Artificial Neural Unit
- 多层感知机Multi-Layer Perception(MLP)
- 激活函数Activation function
- 反向传播Back Propagation
- 学习率Learning Rate
- 损失函数Loss Function(MSE均方误差,Cross Entropy(CE)交叉熵:softmax函数)
- 权值初始化Initialization (Xavier初始化,MSRA初始化)
- 正则化Regularization(Dropout随机失活)
- training set
- 60% data
- validation set
- 20% data
- Testing set
- 20% data
k fold cross validtion
在 K-Fold 的方法中我們會將資料切分為 K 等份,K 是由我們自由調控的,以下圖為例:假設我們設定 K=10,也就是將訓練集切割為十等份。這意味著相同的模型要訓練十次,每一次的訓練都會從這十等份挑選其中九等份作為訓練資料,剩下一等份未參與訓練並作為驗證集。
Activation Function
| Activation Function | Formula | Range |
|---|---|---|
| Tanh | ||
| Sigmoid (Logistic) | ||
| ReLU | ||
| SoftPlus |
scale features (nomralize)
Certainly! Here’s a markdown table summarizing the formulas for different types of feature scaling:
| Scaling Method | Formula | Range |
|---|---|---|
| Z-Score Normalization | ||
| Min-Max Scaling | ||
| Maximum Absolute Scaling | ||
| Robust Scaling |
Clustering Algorithms
- Partition algorithms
- K means clustering
- Gaussian Mixture Model
- Hierarchical algorithms
- Bottom-up, agglomerative
- Top-down, divisive
K means
give K point move point to find position fit all data
K-Medoids
group some point and find the mass center if the point is close merge in to the group if is far then remove from the group
Hierarchical Clustering(Bottom-up)
merge all point by dstance of clusters
distance of clusters
- single-link(closest point of group)
- complete-link(farthest point of group)
- centroid(centers point of group)
- average-link (average distance between of all elements of group)
weight vs unweight
use point number of group as weight or averge two group distance
DBSCAN (Bottom-up)
- start with every point as group it self
- if a,b group are in range of “high densty area” then merge as same group
pattern mining
FP tree
rule (is the itemset are frequent itemset)
if lift(A,B) >1 then A,B is effective
pattern type
- Rare Patterns
- Negative Patterns(Unlikely to happen together)
- Kulczynski(A,B) Less than threshold
- Multilevel Associations
- Multidimensional Associations
constrant type
pruning Strategies
use diff condiation to pruning the iteamset early
- Monotonic(相關性):
- If c is satisfied, no need to check c again
- Anti-monotonic:
- If constraint c is violated, its further mining can be terminated
- Convertible:
- c can be converted to monotonic or anti-monotonic if items can be properly ordered in processing
- Succinct:
- If the constraint c can be enforced by directly manipulating the dat
Sequential Patterns
items within an element are unordered and we list them alphabetically <a(bc)dc> is a subsequence of <a(abc)(ac)d(cf)>
Representative algorithms
- GSP (Generalized Sequential Patterns):
- Generate “length-(k+1)” candidate sequences from “length-k” frequent sequences using Apriori
- Vertical format-based mining: SPADE (Zaki@Machine Leanining’00)
- Pattern-growth methods: PrefixSpan
dimensionality reduction(降维)
PCA(Principal component analysis )
PCoA(principal coordinate analysis )
SVD(Singular Vector Decomposition )
data science
5v
- volume
- variety
- value
- velocity
- veracity
data processing chain
- data
- database
- data store
- data ming
- data value
data warehouse
- subject oriented
- integrate
- non-volatile
- time variant
data warehouse type
- 星形
- 雪花
- 實例星座
data type
| name | exmple |
|---|---|
| nominal data , unordered collection,明目 | dog cat name |
| ordinal data , ordered data ,次序 | level |
| interval data , equal intervals,(not Ture zero)(相除 不可代表比值),區間 | 溫度 |
| ratio data , fraction data,比值 | float |
| BLOB(binary large objects) | image sound file |
Quantile
Q1:small 0%~25%
Q2:small 25%~50%
Q3:small 50%~75%
Q4:small 75%~100%(the biggest)
interQuartile range:Q3-Q1
confusion matrix
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive (True) | TP | FN |
| Actual Negative (False) | FP | TN |
ROC curve
correlations
linear regression
similar function
| h1 | h2 | h3 | h4 | |
|---|---|---|---|---|
| a | 1 | _ | _ | 0.5 |
| b | 0.5 | _ | 0.3 | _ |
| c | _ | 0.7 | _ | 0.4 |
jaccard similarity
cosine similarity
peason correlation coeffiecient
Feature Selection Methods
- Filter methods
- Wrapper methods
- Embedded methods
Classification
Decision Tree
entropy(熵)
Information Gain(IG)
if then entropy is geting less then it is good divide point
gini index(Impurity)
random forest(Bootstrap Aggregation for decision tree)
use mutilple random Decision Tree to vote asnwer
naive bayes
zero conditional(when probability is zero)
t :possible condition number
n :case number
c :possble c
m :virtual sample
Bayesian Network
Bayesian networks are directed and acyclic, whereas Markov networks are undirected and could be cyclic.
SVM(Support Vector Machines)
linear separable SVM
linear inseparable SVM
map data to higher dimension
KNN( K Nearest Neighbor)
- KNN 的演算法步驟如下:
- KNN 中的 K 代表找出距離你最近的 K 筆資料進行分類。
- 假設 K 是 3,代表找出前三筆相近的資料。
- 當這 K 筆資料被選出後,就以投票的方式統計哪一種類的資料量最多,然後就被分到哪一個類別。
Linear Classifiers
Logistic Regression
Gradient Descent
Coordinate Descent
Coordinate descent updates one parameter at a time, while gradient descent attempts to update all parameters at once
Improve Classification Accuracy
Bagging:Bootstrap aggregating
給定一個大小為 n 的訓練集 D,Bagging算法從中均勻、有放回地(即使用自助抽樣法)選出 m個大小為 的子集 ,作為新的訓練集。在這 m 個訓練集上使用分類、回歸等算法,則可得到 m 個模型,在透過取平均值、取多數票等方法,即可得到Bagging的結果。
Boosting
- A series of k classifiers are iteratively learned
- After a classifier Mi is learned, set the subsequent classifier, Mi+1, to pay more
- attention to the training tuples that were misclassified by Mi
- The final M* combines the votes of each individual classifier, where the weight of each classifier’s vote is a function of its accuracy
Imbalanced Data Sets
- Oversampling: Oversample the minority class.
- Under-sampling: Randomly eliminate tuples from majority class
- Synthesizing: Synthesize new minority classes
- Threshold-moving
- Move the decision threshold, t, so that the rare class tuples are easier to classify, and hence, less chance of costly false negative errors
MLP(ANN)
- 人工神经元Artificial Neural Unit
- 多层感知机Multi-Layer Perception(MLP)
- 激活函数Activation function
- 反向传播Back Propagation
- 学习率Learning Rate
- 损失函数Loss Function(MSE均方误差,Cross Entropy(CE)交叉熵:softmax函数)
- 权值初始化Initialization (Xavier初始化,MSRA初始化)
- 正则化Regularization(Dropout随机失活)
- training set
- 60% data
- validation set
- 20% data
- Testing set
- 20% data
k fold cross validtion
在 K-Fold 的方法中我們會將資料切分為 K 等份,K 是由我們自由調控的,以下圖為例:假設我們設定 K=10,也就是將訓練集切割為十等份。這意味著相同的模型要訓練十次,每一次的訓練都會從這十等份挑選其中九等份作為訓練資料,剩下一等份未參與訓練並作為驗證集。
Activation Function
| Activation Function | Formula | Range |
|---|---|---|
| Tanh | ||
| Sigmoid (Logistic) | ||
| ReLU | ||
| SoftPlus |
scale features (nomralize)
Certainly! Here’s a markdown table summarizing the formulas for different types of feature scaling:
| Scaling Method | Formula | Range |
|---|---|---|
| Z-Score Normalization | ||
| Min-Max Scaling | ||
| Maximum Absolute Scaling | ||
| Robust Scaling |
Clustering Algorithms
- Partition algorithms
- K means clustering
- Gaussian Mixture Model
- Hierarchical algorithms
- Bottom-up, agglomerative
- Top-down, divisive
K means
give K point move point to find position fit all data
K-Medoids
group some point and find the mass center if the point is close merge in to the group if is far then remove from the group
Hierarchical Clustering(Bottom-up)
merge all point by dstance of clusters
distance of clusters
- single-link(closest point of group)
- complete-link(farthest point of group)
- centroid(centers point of group)
- average-link (average distance between of all elements of group)
weight vs unweight
use point number of group as weight or averge two group distance
DBSCAN (Bottom-up)
- start with every point as group it self
- if a,b group are in range of “high densty area” then merge as same group
pattern mining
FP tree
rule (is the itemset are frequent itemset)
if lift(A,B) >1 then A,B is effective
pattern type
- Rare Patterns
- Negative Patterns(Unlikely to happen together)
- Kulczynski(A,B) Less than threshold
- Multilevel Associations
- Multidimensional Associations
constrant type
pruning Strategies
use diff condiation to pruning the iteamset early
- Monotonic(相關性):
- If c is satisfied, no need to check c again
- Anti-monotonic:
- If constraint c is violated, its further mining can be terminated
- Convertible:
- c can be converted to monotonic or anti-monotonic if items can be properly ordered in processing
- Succinct:
- If the constraint c can be enforced by directly manipulating the dat
Sequential Patterns
items within an element are unordered and we list them alphabetically <a(bc)dc> is a subsequence of <a(abc)(ac)d(cf)>
Representative algorithms
- GSP (Generalized Sequential Patterns):
- Generate “length-(k+1)” candidate sequences from “length-k” frequent sequences using Apriori
- Vertical format-based mining: SPADE (Zaki@Machine Leanining’00)
- Pattern-growth methods: PrefixSpan
dimensionality reduction(降维)
PCA(Principal component analysis )
PCoA(principal coordinate analysis )
SVD(Singular Vector Decomposition )
hw1 110590049
tags data
2023 Educational Data Mining and Applications HW1.pdf
2.2(e)
Five number summary: min, Q1, median, Q3, max
| min | Q1 | median | Q3 | max |
|---|---|---|---|---|
| 13 | 20 | 25 | 35 | 70 |
2.2(f)
2.8(a)
following 2D data set
x={1.4,1.6}
| A1 | A2 | |
|---|---|---|
| x1 | 1.5 | 1.7 |
| x2 | 2.0 | 1.9 |
| x3 | 1.6 | 1.8 |
| x4 | 1.2 | 1.5 |
| x5 | 1.5 | 1.0 |
Manhattan distance
| A1 | A2 | distance | |
|---|---|---|---|
| x | 1.4 | 1.6 | 0 |
| x1 | 1.5 | 1.7 | 0.2 |
| x4 | 1.2 | 1.5 | 0.3 |
| x3 | 1.6 | 1.8 | 0.4 |
| x5 | 1.5 | 1.0 | 0.5 |
| x2 | 2.0 | 1.9 | 0.9 |
Euclidean distance
| A1 | A2 | distance | rank | |
|---|---|---|---|---|
| x | 1.4 | 1.6 | 0 | |
| x1 | 1.5 | 1.7 | 0.141 | 1 |
| x2 | 2.0 | 1.9 | 0.670 | 5 |
| x3 | 1.6 | 1.8 | 0.282 | 3 |
| x4 | 1.2 | 1.5 | 0.223 | 2 |
| x5 | 1.5 | 1.0 | 0.508 | 4 |
supremum distance
| A1 | A2 | distance | rank | |
|---|---|---|---|---|
| x | 1.4 | 1.6 | 0 | |
| x1 | 1.5 | 1.7 | 0.1 | 1 |
| x2 | 2.0 | 1.9 | 0.6 | 5 |
| x3 | 1.6 | 1.8 | 0.2 | 3 |
| x4 | 1.2 | 1.5 | 0.2 | 2 |
| x5 | 1.5 | 1.0 | 0.4 | 4 |
cosine similarity
| A1 | A2 | similarity | rank | |
|---|---|---|---|---|
| x | 1.4 | 1.6 | 0 | |
| x1 | 1.5 | 1.7 | 0.9999 | 1 |
| x2 | 2.0 | 1.9 | 0.9957 | 3 |
| x3 | 1.6 | 1.8 | 0.9999 | 2 |
| x4 | 1.2 | 1.5 | 0.9990 | 5 |
| x5 | 1.5 | 1.0 | 0.9653 | 4 |
2.8(b)
| A1 | A2 | distance | rank | |
|---|---|---|---|---|
| x | 0.658 | 0.752 | 0 | |
| x1 | 0.661 | 0.749 | 0.0042 | 1 |
| x2 | 0.642 | 0.789 | 0.0403 | 3 |
| x3 | 0.724 | 0.688 | 0.0919 | 4 |
| x4 | 0.664 | 0.747 | 0.0078 | 2 |
| x5 | 0.832 | 0.554 | 0.2635 | 5 |
3.3(a)
| Bin | Data |
|---|---|
| Bin 1 | 13, 15, 16 |
| Bin 2 | 16, 19, 20 |
| Bin 3 | 20, 21, 22 |
| Bin 4 | 22, 25, 25 |
| Bin 5 | 25, 25, 30 |
| Bin 6 | 33, 33 ,35 |
| Bin 7 | 35, 35, 35 |
| Bin 8 | 35, 35, 36 |
| Bin 9 | 36, 40, 45 |
| Bin 10 | 46, 52, 70 |
| Bin | Smoothed Data |
|---|---|
| Bin 1 | 14.67, 14.67, 14.67 |
| Bin 2 | 18.33, 18.33, 18.33 |
| Bin 3 | 21.00, 21.00, 21.00 |
| Bin 4 | 24.00, 24.00, 24.00 |
| Bin 5 | 26.67, 26.67, 26.67 |
| Bin 6 | 33.67, 33.67, 33.67 |
| Bin 7 | 35.00, 35.00, 35.00 |
| Bin 8 | 35.33, 35.33, 35.33 |
| Bin 9 | 40.33, 40.33, 40.33 |
| Bin 10 | 56.00, 56.00, 56.00 |
3.3(b)
find the outlier value using the IQR method:
3.7(a)
3.7(b)
3.8(b)
| age | fat |
|---|---|
| 23 | 9.5 |
| 23 | 26.5 |
| 27 | 7.8 |
| 27 | 17.8 |
| 39 | 31.4 |
| 41 | 25.9 |
| 47 | 27.4 |
| 49 | 27.2 |
| 50 | 31.2 |
| 52 | 34.6 |
| 54 | 28.8 |
| 56 | 33.4 |
| 57 | 30.2 |
| 58 | 34.1 |
| 58 | 32.9 |
| 60 | 41.2 |
| 61 | 35.7 |
3.11(a)
hw2 110590049
tags data
2023 Educational Data Mining and Applications HW2.pdf
6.3
a
- Support(L) ≥ minimum support threshold.
- Since S is a subset of L, it means that any transaction containing all items in S also contains all items in L.
- Support(S) ≥ Support(L) (because S includes all transactions that L includes)
- Therefore, Support(S) ≥ minimum support threshold.
- This proves that S is also a frequent itemset.
b
- S’ ⊆ S
- {T ∈ D | S ⊆ T} = Support(S) , all possible set T that is the superset of S
- {T ∈ D | S ⊆ T} ⊆ {T ∈ D | S’ ⊆ T}
- Support(S) ≤ Support(S’)
c
- Confidence(X => Y) = Support(X ∪ Y) / Support(X).
- Confidence(s => {l-s}) = Support(s ∪ {l-s}) / Support({l-s}).
- Confidence(s’ => {l-s’}) = Support(s’ ∪ {l-s’}) / Support({l-s’}).
- Support(s’ ∪ (l - s’)) ≤ Support(s ∪ (l - s))
- Support(s’) ≤ Support(s)
- Confidence(s’ => (l - s’)) ≤ Confidence(s => (l - s))
d
- If I is frequent in D, it must have a support count greater than or equal to the minimum support count threshold (minsup) for frequent itemsets in D.
- If I is not frequent in any partition Pi, it must have a support count less than the minsup in each partition.
- Any itemset that is frequent in the original database D must be frequent in at least one partition of D.
6.6
min_support=0.6
min_confi=0.8
| ID | Items |
|---|---|
| T100 | {M, O, N, K, E, Y} |
| T200 | {D, O, N, K, E, Y} |
| T300 | {M, A, K, E} |
| T400 | {M, U, C, K, Y} |
| T500 | {C, O, O, K, I, E} |
a
Apriori algorithm
| 1-Itemsets | 2-Itemsets | 3-Itemsets | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
FP-growth algorithm
| itemsets | condition | support 0.6 itemsets | frequent itemsets |
|---|---|---|---|
| e | {k:4} | {k:4} | |
| m | {e,k:2},{k:1} | {k:3} | |
| o | {k,e,m:1},{k,e:2} | {k,3}{e:3} | |
| y | {k,e,m:1},{k,e,o:1},{k,m:1} | {k:3} |
conclusion
By query 2 time to build FP-tree reduce the time to query database .So FP-growth is more efficient compared to a priori.
b
| frequent itemsets | support | Confidence |
|---|---|---|
| 0.6 | 1.0 | |
| 0.6 | 1.0 |
6.14
| hot | dogs | !(hot dogs) | total |
|---|---|---|---|
| hamburgers | 2000 | 500 | 2500 |
| !(hamburgers) | 1000 | 1500 | 2500 |
| Total | 3000 | 2000 | 5000 |
a
b
c
hw3 110590049
tags data
2023 Educational Data Mining and Applications HW3.pdf
8.11
8.12
| sample | threshold sample | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
ROC
8.16
change the traing dataset to balance by oversampleing the fraudulent cases or undersampling nonfraudulent cases.
by threshold-moving to reduce the error chance on majority case
9.4
| Eager Classification | Lazy Classification | |
|---|---|---|
| Advantage | Better interpretability Better efficiency | Robust to Noise |
| Disadvantage | Robust to Noise Need for re-training when have new data | Vulnerability to irrelevant features Limited interpretability |
9.5
def distance(a,b):
return sum([abs(a[i]-b[i]) for i in range(len(a))])
def KNN(input_data,k,dataset,answer):
distances=[]
i=0
for data in dataset :
distances.append({
"distance":distance(input_data,data),
"answer":answer[i]
})
i+=1
nesrest=sorted(distances,key=lambda x:x["distance"])[:k]
counter={key:0 for key in answer}
for x in nesrest:
counter[x["answer"]]+=1
predict={key:counter[key]/k for key in counter}
return predict
data=[[1,2,3],[0,-1,0],[1,4,4],[1,3,4]]
answer=["a","a","b","b"]
input_data=[0,0,0]
k=3
print(KNN(input_data,k,data,answer))
database systems
Three-schema Architecture
- Internal level
- how data actually store in database
- Conceptual level
- use some ER Diagram to desc main conceptual of data structure
- External level
- how to present to out world (interface)
Database constraint
- Implicit Constraints or Inherent constraint
- Constraints that are applied in the data model
- Schema-Based Constraints or Explicit Constraints
- Constraints that are directly applied in the schemas of the data model, by specifying them in the DDL(Data Definition Language).
- Semantic Constraints or Application based
- Constraints that cannot be directly applied in the schemas of the data model. We call these Application based or .
Database Independence
- Logical Data Independence:
- The capacity to change the conceptual schema without having to change the external schemas and their associated application programs
- Physical Data Independence:
- The capacity to change the internal schema without having to change the conceptual schema.
Three-tier client-server architecture
- presentation layer
- GUI, web interface
- busincess layer
- application programs
- database services layer
- database management system
superkey
null
A special null value is used to represent values that are unknown or not available (value exist) or inapplicable (value undefined) in certain tuples.
EER diagram
total vs partial | disjoint vs overlapped
| total | partial | disjoint | overlapped | |
|---|---|---|---|---|
| EER diagram | double line | single line | d | o |
| super class inheritance | at least one subclass | can be none | at most one | can more than one |
- specialization:
- top down conceptual refinement process
- arrow to subclass
- generalization:
- bottom up conceptual synthesis process
- arrow to superclass
- shared subclass:
- multiple super class
- multiple inheritance from diff super class
- presend subclass is intersection of super class
- Categories (UNION TYPES):
- presend subclass is union of super class
- use “U” as symbol in EER diagram
sql
HOTEL(hotelNo, hoteName, City);
ROOM(roomNo, hotelNo, type, price);
BOOKING(hotelNoguestNo, dateFrom, dateTo, foomNo);
GUEST(guestNo, guestName, guestAddress);
List the price and type of all rooms that hotelName is Howard Hotel.
SELECT r.price, r.type
FROM ROOM r
INNER JOIN HOTEL h ON r.hotelNo = h.hotelNo
WHERE h.hotelName = 'Howard Hotel';
SELECT price, type
FROM ROOM
WHERE hotelNo = (SELECT hotelNo FROM HOTEL WHERE hotelName = 'Howard Hotel');
List the details of all rooms at the Howard Hotel, including the name of the guest staying in the room if the room is occupied.
SELECT r.roomNo, r.type, r.price, g.guestName
FROM ROOM r
LEFT JOIN BOOKING b ON r.roomNo = b.roomNo
LEFT JOIN GUEST g ON b.guestNo = g.guestNo
INNER JOIN HOTEL h ON r.hotelNo = h.hotelNo
WHERE h.hotelName = 'Howard Hotel';
List all single rooms with a price below 3,000 per night. ) (4%) List all guests currently staying at the Howard Hotel.
SELECT r.roomNo, r.price
FROM ROOM r
WHERE r.type = 'single' AND r.price < 3000;
list all guests currently staying at the “Howard Hotel,”
SELECT DISTINCT g.guestName
FROM GUEST g
INNER JOIN BOOKING b ON g.guestNo = b.guestNo
WHERE b.hotelNo = (SELECT hotelNo FROM HOTEL WHERE hotelName = 'Howard Hotel');
execpt
SELECT Fname, Lname
FROM Employee
WHERE NOT EXISTS((SELECT Pnumber
FROM PROJECT
WHERE Dno=5)
EXCEPT(SELECT Pno
FROM WORKS_ON
WHERE Ssn= ESsn));
schemas
join vs. sub-query
In general join have better performance because of optimisers.
正規化 (normalization)
- make sure attribute semantics are clear
- reducing redundant information
- candidate key: If a relation schema has more than one key, each is called a candidate key
- Prime attribute: Prime attribute must be a member of some candidate key
Functional Dependency
mean if get x and y can get z
partial dependency
but x alone can get z then it is partial dependency
Fully Functional Dependency
not partial dependency
transitive dependency
and y is not candidate key then it is transitive dependency
multivalued dependency
if y is the subset of x then this is multivalued dependency
join dependency | dependency preservation
1NF
- must be a primary key for identification
- no duplicated rows or columns
- no nest relations(JSON)
- no composite attributes (struct)
- no multivalued attributes (array)
2NF
- 1NF
- no partial dependency
- All attributes depend on the whole key
- No partial dependencies on the primary key (for nonprime attributes)
3NF
- 2NF
- All attributes depend on nothing but the key
- No transitive dependencies on the primary key (for nonprime attribute
BCNF or 3.5NF (Boyce-Codd Normal Form)
- 3NF
- all key of table cant depend on another non-key columns
4NF
- if, for every nontrivial multivalued dependency x is superkey
- not only can save on storage, but also avoid the update anomalies
5NF
- The constraint states that every legal state r of R should have a non-additive join decomposition into R1, R2, …, Rn; that is, for every such r we have
NF example
2NF
3NF
4NF 5NF
disk
- Seek time: position the read/write head on the correct track
- Rotational delay or latency: the beginning of the desired block rotates into position under the read/write head
- Block transfer time: transfer the data of the desired block
- Blocking factor (bfr): refers to the number of records per block
- primary file organizations
- records of a file are physically placed on the disk
- how the records can be accessed
- e.g.heap, sorted, hashed, B-tree
buffering
double buffering
- ite continuous stream of blocks from memory to the disk
- Permits continuous reading or writing of data on consecutive disk blocks, which eliminates the seek time and rotational delay for all but the first block transfer
Buffer Management
Buffer manager is a software component of a DBMS that responds to requests for data and decides what buffer to use and what pages to replace in the buffer to accommodate the newly requested blocks
- Controls the main memory directly as in most RDBMS
- Allocate buffers in virtual memory, which allows the control to transfer to the operating system (OS
data requested workflow
- checks if the requested page is already in a buffer in the buffer pool; if so, it increments its pin-count and release the page
- If the page is not in the buffer pool, the buffer manager does the following
- It chooses a page for replacement, using the replacement policy, and increments its pin-count
- If the dirty bit of the replacement page is on, the buffer manager writes that page to disk by replacing its old copy on disk. If the dirty it is not on, no need to write
- The main memory address of the new page is passed to the requesting application
Buffer Replacement Strategies
- Least recently used (LRU)
- Clock policy (a round-robin variant of the LRU)
- First-in-first-out (FIFO)
- Most recently used (MRU)
record
- fixed length
- variable length
- variable field (varying size)
- repeating field (multiple values)
- optional field (optional)
file
- Unspanned: no record can span two blocks
- Spanned: a record can be stored in more than one block
unorder file
- linear search
- heap or pile file
- Record insertion is quite efficient
- deletion marker
order file
- sequential
- sorted
- binary search
clustered index(B-Tree)
primary index is leaf index of tree
not clustered index
hash file
directories can be stored on disk, and they expand or shrink dynamically
deal with collision
- Chaining: use link list to chaining data
- Rehashing
- Open Addressing
static hashing
- order access is inefficient
dynamic Hashing
- directory is a binary tree
extendible hashing
- directory is an array of size where is called the global depth
Linear hashing
- not use a directory
RAID
- Improve reliability: by storing redundant information on disks using parity or some other error correction code
- transfer rate: high overall transfer rate and also accomplish load balancing
- performance: improve disk performance
- data striping
- Bit-level data striping
- Splitting a byte of data and writing bit j to the jth disk
- Can be generalized to a number of disks that is either a multiple or a factor of eight
- Block-level data striping
- separate disks to reduce queuing time of I/O reques
- arge requests (accessing multiple blocks) can be parallelized to reduce the response time
- Bit-level data striping
NAS(Network-Attached Storage)
- file sharing
- low cost
SAN(Storage Area Networks)
- Flexible: many-to-many connectivity among servers and storage devices using fiber channel hubs and switches
- Better isolation capabilities allowing non-disruptive addition of new peripherals and servers
index
- primary index: must be defined on an ordered key field.
- clustered index: must be defined on an order field (not keyed) allowing for ranges of records with identical index field values.
- secondary index: is defined on any non-ordered (keyed or non-key) field.
database systems
Three-schema Architecture
- Internal level
- how data actually store in database
- Conceptual level
- use some ER Diagram to desc main conceptual of data structure
- External level
- how to present to out world (interface)
Database constraint
- Implicit Constraints or Inherent constraint
- Constraints that are applied in the data model
- Schema-Based Constraints or Explicit Constraints
- Constraints that are directly applied in the schemas of the data model, by specifying them in the DDL(Data Definition Language).
- Semantic Constraints or Application based
- Constraints that cannot be directly applied in the schemas of the data model. We call these Application based or .
Database Independence
- Logical Data Independence:
- The capacity to change the conceptual schema without having to change the external schemas and their associated application programs
- Physical Data Independence:
- The capacity to change the internal schema without having to change the conceptual schema.
Three-tier client-server architecture
- presentation layer
- GUI, web interface
- busincess layer
- application programs
- database services layer
- database management system
superkey
null
A special null value is used to represent values that are unknown or not available (value exist) or inapplicable (value undefined) in certain tuples.
EER diagram
total vs partial | disjoint vs overlapped
| total | partial | disjoint | overlapped | |
|---|---|---|---|---|
| EER diagram | double line | single line | d | o |
| super class inheritance | at least one subclass | can be none | at most one | can more than one |
- specialization:
- top down conceptual refinement process
- arrow to subclass
- generalization:
- bottom up conceptual synthesis process
- arrow to superclass
- shared subclass:
- multiple super class
- multiple inheritance from diff super class
- presend subclass is intersection of super class
- Categories (UNION TYPES):
- presend subclass is union of super class
- use “U” as symbol in EER diagram
sql
HOTEL(hotelNo, hoteName, City);
ROOM(roomNo, hotelNo, type, price);
BOOKING(hotelNoguestNo, dateFrom, dateTo, foomNo);
GUEST(guestNo, guestName, guestAddress);
List the price and type of all rooms that hotelName is Howard Hotel.
SELECT r.price, r.type
FROM ROOM r
INNER JOIN HOTEL h ON r.hotelNo = h.hotelNo
WHERE h.hotelName = 'Howard Hotel';
SELECT price, type
FROM ROOM
WHERE hotelNo = (SELECT hotelNo FROM HOTEL WHERE hotelName = 'Howard Hotel');
List the details of all rooms at the Howard Hotel, including the name of the guest staying in the room if the room is occupied.
SELECT r.roomNo, r.type, r.price, g.guestName
FROM ROOM r
LEFT JOIN BOOKING b ON r.roomNo = b.roomNo
LEFT JOIN GUEST g ON b.guestNo = g.guestNo
INNER JOIN HOTEL h ON r.hotelNo = h.hotelNo
WHERE h.hotelName = 'Howard Hotel';
List all single rooms with a price below 3,000 per night. ) (4%) List all guests currently staying at the Howard Hotel.
SELECT r.roomNo, r.price
FROM ROOM r
WHERE r.type = 'single' AND r.price < 3000;
list all guests currently staying at the “Howard Hotel,”
SELECT DISTINCT g.guestName
FROM GUEST g
INNER JOIN BOOKING b ON g.guestNo = b.guestNo
WHERE b.hotelNo = (SELECT hotelNo FROM HOTEL WHERE hotelName = 'Howard Hotel');
execpt
SELECT Fname, Lname
FROM Employee
WHERE NOT EXISTS((SELECT Pnumber
FROM PROJECT
WHERE Dno=5)
EXCEPT(SELECT Pno
FROM WORKS_ON
WHERE Ssn= ESsn));
schemas
join vs. sub-query
In general join have better performance because of optimisers.
正規化 (normalization)
- make sure attribute semantics are clear
- reducing redundant information
- candidate key: If a relation schema has more than one key, each is called a candidate key
- Prime attribute: Prime attribute must be a member of some candidate key
Functional Dependency
mean if get x and y can get z
partial dependency
but x alone can get z then it is partial dependency
Fully Functional Dependency
not partial dependency
transitive dependency
and y is not candidate key then it is transitive dependency
multivalued dependency
if y is the subset of x then this is multivalued dependency
join dependency | dependency preservation
1NF
- must be a primary key for identification
- no duplicated rows or columns
- no nest relations(JSON)
- no composite attributes (struct)
- no multivalued attributes (array)
2NF
- 1NF
- no partial dependency
- All attributes depend on the whole key
- No partial dependencies on the primary key (for nonprime attributes)
3NF
- 2NF
- All attributes depend on nothing but the key
- No transitive dependencies on the primary key (for nonprime attribute
BCNF or 3.5NF (Boyce-Codd Normal Form)
- 3NF
- all key of table cant depend on another non-key columns
4NF
- if, for every nontrivial multivalued dependency x is superkey
- not only can save on storage, but also avoid the update anomalies
5NF
- The constraint states that every legal state r of R should have a non-additive join decomposition into R1, R2, …, Rn; that is, for every such r we have
NF example
2NF
3NF
4NF 5NF
disk
- Seek time: position the read/write head on the correct track
- Rotational delay or latency: the beginning of the desired block rotates into position under the read/write head
- Block transfer time: transfer the data of the desired block
- Blocking factor (bfr): refers to the number of records per block
- primary file organizations
- records of a file are physically placed on the disk
- how the records can be accessed
- e.g.heap, sorted, hashed, B-tree
buffering
double buffering
- ite continuous stream of blocks from memory to the disk
- Permits continuous reading or writing of data on consecutive disk blocks, which eliminates the seek time and rotational delay for all but the first block transfer
Buffer Management
Buffer manager is a software component of a DBMS that responds to requests for data and decides what buffer to use and what pages to replace in the buffer to accommodate the newly requested blocks
- Controls the main memory directly as in most RDBMS
- Allocate buffers in virtual memory, which allows the control to transfer to the operating system (OS
data requested workflow
- checks if the requested page is already in a buffer in the buffer pool; if so, it increments its pin-count and release the page
- If the page is not in the buffer pool, the buffer manager does the following
- It chooses a page for replacement, using the replacement policy, and increments its pin-count
- If the dirty bit of the replacement page is on, the buffer manager writes that page to disk by replacing its old copy on disk. If the dirty it is not on, no need to write
- The main memory address of the new page is passed to the requesting application
Buffer Replacement Strategies
- Least recently used (LRU)
- Clock policy (a round-robin variant of the LRU)
- First-in-first-out (FIFO)
- Most recently used (MRU)
record
- fixed length
- variable length
- variable field (varying size)
- repeating field (multiple values)
- optional field (optional)
file
- Unspanned: no record can span two blocks
- Spanned: a record can be stored in more than one block
unorder file
- linear search
- heap or pile file
- Record insertion is quite efficient
- deletion marker
order file
- sequential
- sorted
- binary search
clustered index(B-Tree)
primary index is leaf index of tree
not clustered index
hash file
directories can be stored on disk, and they expand or shrink dynamically
deal with collision
- Chaining: use link list to chaining data
- Rehashing
- Open Addressing
static hashing
- order access is inefficient
dynamic Hashing
- directory is a binary tree
extendible hashing
- directory is an array of size where is called the global depth
Linear hashing
- not use a directory
RAID
- Improve reliability: by storing redundant information on disks using parity or some other error correction code
- transfer rate: high overall transfer rate and also accomplish load balancing
- performance: improve disk performance
- data striping
- Bit-level data striping
- Splitting a byte of data and writing bit j to the jth disk
- Can be generalized to a number of disks that is either a multiple or a factor of eight
- Block-level data striping
- separate disks to reduce queuing time of I/O reques
- arge requests (accessing multiple blocks) can be parallelized to reduce the response time
- Bit-level data striping
NAS(Network-Attached Storage)
- file sharing
- low cost
SAN(Storage Area Networks)
- Flexible: many-to-many connectivity among servers and storage devices using fiber channel hubs and switches
- Better isolation capabilities allowing non-disruptive addition of new peripherals and servers
index
- primary index: must be defined on an ordered key field.
- clustered index: must be defined on an order field (not keyed) allowing for ranges of records with identical index field values.
- secondary index: is defined on any non-ordered (keyed or non-key) field.
hw1 110590049
tags db database
1.
install steps
commands
2. main characteristies
- Self-describing:
A DBMS catalog stores the description of a particular database (e.g. data structures, types, and constraints) - Insulation between programs and data:
program-data independence
3.a data model
Set of concepts to describe the structure of a database, the operations for manipulating these structures, and certain constraints that the database should obey.
3.b database schema
The description of a database. Includes descriptions of the database structure, data types, and the constraints on the database.
4.Three-Schema Architecture
- Internal schema: at the internal level to describe physical storage structures and access paths
- Conceptual schema: at the conceptual level to describe the structure and constraints for the whole database for a community of users.
5.For the binary relationships below,suggest cardinality ratios based on common-sense meaning of the entity types. Clearly state any assumptions you make
| Entity1 | Cardinality Ratio | Entity2 | Reason |
|---|---|---|---|
| Student | 1:N | Book | A book can only be own by one person at the same time. |
| Student | N:1 | Advisor | One advisor can have multiple students, but a student can only be connected to one advisor at a time. |
| ClassRoom | N:M | Wall | Walls can be shared by multiple classrooms, and a class can have multiple walls. |
| Student | N:M | Course | Reason: Students can be enrolled in multiple courses, and a course can have multiple students at the same time. |
| Car | 1:1 | Engine | One car should only have one engine at a time. |
6.a
| Entity1 | Cardinality Ratio | Entity2 | Reason |
|---|---|---|---|
| Student ID No. | 1:1 | ID No. | one person only have one ID number |
| Student ID No. | 1:1 | Name | one student only have one name |
| Student ID No. | 1:1 | Cellphone | one student only have one phone |
| Student ID No. | 1:1 | Signature | one student only have one signature |
| Student ID No. | 1:N | No. | one student can have multiple suspension |
| No. | 1:1 | Class | only suspension one class at time |
| No. | 1:1 | Date of application | one form only have one application time |
| No. | 1:1 | Date of Resumption | one form only have one resumption time |
| No. | 1:1 | Application | one form can only have one type of application |
| No. | 1:1 | Department/Graduate Institute | one form can only have one Department or Graduate Institues |
| No. | 1:1 | Reason for Suspension | one form only have one reason of suspension |
| No. | 1:1 | Suspension | one form only have one status of suspenstion |
| No. | 1:1 | Sigend by Parent | one form only have one signed |
| No. | 1:1 | Address | one form only have one address |
6.b

hw2 110590049
tags db database
1.
The doctor could also be a patient. Additionally, the pharmacy can sell drugs from pharmaceutical companies at different prices compared to other pharmacies.
The key icon stands for primary key. On the other side of the connection with the primary key is the foreign key.
2.
The key icon stands for primary key. On the other side of the connection with the primary key is the foreign key.
3.
3.a
有違反 Semantic Integrity Constraints,Robert 的上司是 James(888665555) ,但 Robert 的薪水(58000)比上司(55000)還高 No integrity constraints are violated.
3.b
The DEPT_LOCATIONS number should be 5, but this operation inserts 2 into it, resulting in inconsistency in the DEPT_LOCATIONS number.
3.c
No integrity constraints are violated.
3.d
Delete the PROJECT “ProductX” from the PROJECT table, and also delete the tuple from the WORKS_ON table where “Pno” is “1.”
3.e
No integrity constraints are violated.
3.f
If you modify the Pnumber from 30 to 40, you also need to change the row in the WORKS_ON table where Pno is 30 to 40. This will result in inconsistency within the WORKS_ON table.
4.
hw3 110590049
tags db database
1
| table | column | ||||
|---|---|---|---|---|---|
| PREREQUISITE | CourseNumber | PrerequisiteCourseNumber | |||
| GRADE_REPORT | StudentNumber | SectionNumber | Grade | ||
| STUDENT | StudentNumber | Name | Class | Major | |
| COURSE | CourseNumber | CourseName | “CreditHour” | Department | |
| SECTION | SectionNumber | CourseNumber | Semester | Year | Instructor |
a
UPDATE "COURSE"
SET "CreditHour" = 2
WHERE "CourseName" = 'Object-Oriented Programming'
AND "Department" = 'EECS';
b
DELETE FROM "STUDENT"
WHERE Name = 'David'
AND "StudentNumber" = '005';
c
SELECT "COURSE"."CourseName" FROM "SECTION"
LEFT JOIN "COURSE" ON "COURSE"."CourseNumber" = "SECTION"."CourseNumber"
WHERE "Instructor" = 'John'
AND "Year" = 2022;
d
SELECT "S"."CourseNumber", "SE"."Semester", "SE"."Year", COUNT("GR"."StudentNumber") AS "NumberOfStudents"
FROM "SECTION" "SE"
JOIN "COURSE" "S" ON "SE"."CourseNumber" = "S"."CourseNumber"
LEFT JOIN "GRADE_REPORT" "GR" ON "SE"."SectionNumber" = "GR"."SectionNumber"
WHERE "SE"."Instructor" = 'Eric'
GROUP BY "S"."CourseNumber", "SE"."Semester", "SE"."Year";
e
SELECT "P"."PrerequisiteCourseNumber", "PC"."CourseName"
FROM "PREREQUISITE" "P"
JOIN "COURSE" "C" ON "P"."CourseNumber" = "C"."CourseNumber"
JOIN "COURSE" "PC" ON "P"."PrerequisiteCourseNumber" = "PC"."CourseNumber"
WHERE "C"."CourseName" = 'Database Systems' AND "C"."Department" = 'EECS';
f
SELECT "STUDENT"."Name", "COURSE"."CourseNumber", "COURSE"."CourseName", "COURSE"."CreditHour", "SECTION"."Semester", "SECTION"."Year", "GRADE_REPORT"."Grade"
FROM "STUDENT"
JOIN "GRADE_REPORT" ON "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber"
JOIN "SECTION" ON "GRADE_REPORT"."SectionNumber" = "SECTION"."SectionNumber"
JOIN "COURSE" ON "SECTION"."CourseNumber" = "COURSE"."CourseNumber"
WHERE "STUDENT"."Class" = 3 AND "STUDENT"."Major" = 'EECS';
g
SELECT DISTINCT "STUDENT"."Name"
FROM "STUDENT"
WHERE NOT EXISTS (
SELECT *
FROM "GRADE_REPORT"
WHERE "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber" AND "GRADE_REPORT"."Grade" < 80
);
h
SELECT "STUDENT"."Name", "STUDENT"."Major"
FROM "STUDENT"
WHERE NOT EXISTS (
SELECT *
FROM "GRADE_REPORT"
WHERE "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber" AND "GRADE_REPORT"."Grade" < 60
);
i
SELECT DISTINCT "STUDENT"."Name", "STUDENT"."Major"
FROM "STUDENT"
JOIN "GRADE_REPORT" ON "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber"
WHERE "GRADE_REPORT"."Grade" < 60
ORDER BY "STUDENT"."StudentNumber";
j
SELECT "STUDENT"."Name", AVG("GRADE_REPORT"."Grade") AS "AverageGrade"
FROM "STUDENT"
JOIN "GRADE_REPORT" ON "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber"
JOIN "SECTION" ON "GRADE_REPORT"."SectionNumber" = "SECTION"."SectionNumber"
WHERE "SECTION"."Year" = 2023
GROUP BY "STUDENT"."Name"
HAVING AVG("GRADE_REPORT"."Grade") > 80.0;
k
SELECT "STUDENT"."Major", COUNT(DISTINCT "STUDENT"."StudentNumber") AS "NumStudents"
FROM "STUDENT"
JOIN "GRADE_REPORT" ON "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber"
GROUP BY "STUDENT"."Major"
HAVING AVG("GRADE_REPORT"."Grade") < 60.0;
l
CREATE VIEW "StudentTranscript" AS
SELECT "STUDENT"."StudentNumber", "STUDENT"."Name", "COURSE"."CourseName", "SECTION"."Semester", "SECTION"."Year", "GRADE_REPORT"."Grade"
FROM "STUDENT"
JOIN "GRADE_REPORT" ON "STUDENT"."StudentNumber" = "GRADE_REPORT"."StudentNumber"
JOIN "SECTION" ON "GRADE_REPORT"."SectionNumber" = "SECTION"."SectionNumber"
JOIN "COURSE" ON "SECTION"."CourseNumber" = "COURSE"."CourseNumber";
2
a
CREATE TABLE "STUDENT" (
"StudentNumber" INT PRIMARY KEY,
"Name" VARCHAR(255),
"Class" INT,
"Major" VARCHAR(255)
);
CREATE TABLE "COURSE" (
"CourseNumber" INT PRIMARY KEY,
"CourseName" VARCHAR(255),
"CreditHour" INT,
"Department" VARCHAR(255)
);
CREATE TABLE "SECTION" (
"SectionNumber" INT PRIMARY KEY,
"CourseNumber" INT REFERENCES "COURSE"("CourseNumber")ON DELETE CASCADE,
"Semester" VARCHAR(255),
"Year" INT,
"Instructor" VARCHAR(255)
);
CREATE TABLE "GRADE_REPORT" (
"StudentNumber" INT REFERENCES "STUDENT"("StudentNumber")ON DELETE CASCADE,
"SectionNumber" INT REFERENCES "SECTION"("SectionNumber")ON DELETE CASCADE,
"Grade" INT
);
CREATE TABLE "PREREQUISITE" (
"CourseNumber" INT REFERENCES "COURSE"("CourseNumber")ON DELETE CASCADE,
"PrerequisiteCourseNumber" INT REFERENCES "COURSE"("CourseNumber")ON DELETE CASCADE,
PRIMARY KEY ("CourseNumber", "PrerequisiteCourseNumber")
);
b
INSERT INTO "STUDENT" ("StudentNumber", "Name", "Class", "Major") VALUES
(1, 'Alice', 3, 'EECS'),
(2, 'Bob', 2, 'Mathematics'),
(3, 'Charlie', 1, 'Physics'),
(4, 'Eva', 3, 'Computer Science'),
(5, 'David', 2, 'EECS');
-- Sample data for COURSE table
INSERT INTO "COURSE" ("CourseNumber", "CourseName", "CreditHour", "Department") VALUES
(1, 'Introduction to Computer Science', 3, 'EECS'),
(2, 'Linear Algebra', 4, 'Mathematics'),
(3, 'Modern Physics', 3, 'Physics'),
(4, 'Object-Oriented Programming', 3, 'EECS'),
(5, 'Database Systems', 4, 'EECS');
-- Sample data for SECTION table
INSERT INTO "SECTION" ("SectionNumber", "CourseNumber", "Semester", "Year", "Instructor") VALUES
(1, 1, 'Fall', 2022, 'John'),
(2, 2, 'Spring', 2023, 'Alice'),
(3, 4, 'Fall', 2022, 'Eric'),
(4, 5, 'Spring', 2023, 'Bob');
-- Sample data for GRADE_REPORT table
INSERT INTO "GRADE_REPORT" ("StudentNumber", "SectionNumber", "Grade") VALUES
(1, 1, 90),
(2, 2, 85),
(3, 3, 59),
(4, 4, 92),
(5, 1, 88);
-- Sample data for PREREQUISITE table
INSERT INTO "PREREQUISITE" ("CourseNumber", "PrerequisiteCourseNumber") VALUES
(5, 4),
(5, 3),
(2, 1);
c
a
b
c
d
e
f
g
h
i
j
k
l
d
CREATE OR REPLACE FUNCTION get_student_average_grade(student_number INT)
RETURNS varchar AS $$
DECLARE
avg_grade numeric;
result_text varchar;
BEGIN
SELECT AVG("GRADE_REPORT"."Grade") INTO avg_grade
FROM "GRADE_REPORT"
WHERE "GRADE_REPORT"."StudentNumber" = student_number;
IF avg_grade >= 60 THEN
result_text := 'PASS';
ELSE
result_text := 'FAIL';
END IF;
RETURN result_text;
END;
$$ LANGUAGE plpgsql;
hw4 110590049
tags db database
1
1.a
is Key because
- can get
- can get
- can get
1.b
- 2NF: no partial dependcy
1.c
2
FD1={Course_no} → {Offering_dept, Credit_hours, Course_level}
FD2={Course_no, Sec_no, Semester, Year} → {Days_hours, Room_no, No_of_students, Instructor_ssn}
FD3={Room_no, Days_hours, Semester, Year} → {Instructor_ssn, Course_no, Sec_no}
2.a
1NF because:
- FD1 have partial function since Course_no is not key
2.b
- {Course_no, Sec_no, Semester, Year}
- {Room_no, Days_hours, Semester, Year}
2.c
use {Course_no, Sec_no, Semester, Year} as PK
loss FD3 R1 = {Course_no, Offering_dept, Credit_hours, Course_level}
R2 = {Course_no, Sec_no, Semester, Year, Days_hours, Room_no, No_of_students, Instructor_ssn}}
is BCNF
3
- Caching: move disk data to RAM or SSD
- Indexing: use B-trees or hash indexes to speedup the time of searching
- organization of data on disk: keep related data on continuous block
4
4.a
4.b
4.c
4.c.i
4.c.ii
4.c.iii
4.c.iv
4.c.v
4.d
4.d.i
4.d.ii
4.d.iii
4.d.iv
4.d.v
5
- primary index: must be defined on an ordered key field.
- clustered index: must be defined on an order field (not keyed) allowing for ranges of records with identical index field values.
- secondary index: is defined on any non-ordered (keyed or non-key) field.
leetcode
tags: leetcode
22. Generate Parentheses
tags:dfs
class Solution {
public:
std::vector<std::string> ans;
int n;
void gen(string v,int i,int j){
if(i>j)
if(i<n)
gen(v+"(",i+1,j);
if(j<n)
gen(v+")",i,j+1);
if(i==j)
if(j==n)
ans.push_back(v);
else
gen(v+"(",i+1,j);
}
std::vector<std::string> generateParenthesis(int nn) {
n=nn;
gen("(",1,0);
return ans;
}
};
33. Search in Rotated Sorted Array
tags:binary search
class Solution {
public:
int search(vector<int>& nums, int target) {
int l=0;
int bound=nums.size();
int r=bound-1;
if(nums[l]>nums[r]){
//binary search to find the prior point
while(l<r){
int mid=l+(r-l)/2;
if(nums[mid]==target)
return mid;
if(nums[mid]>nums[r])
l=mid+1;
else
r=mid;
}
if(target<=nums[bound-1])
r=bound-1;
else {
r=l;
l=0;
}
}
//binary search
while(l<=r){
int mid=l+(r-l)/2;
if(nums[mid]==target)
return mid;
if(nums[mid]>target)
r=mid-1;
else
l=mid+1;
mid=(l+r)/2;
}
return -1;
}
};
52. N-Queens II
tags:dfs
class Solution {
public:
std::vector<std::vector<std::pair<int, int>>> solve;
bool safeSol(const std::vector<std::pair<int, int>>& queens) {
for (int i = 0; i < queens.size(); i++) {
for (int j = i + 1; j < queens.size(); j++) {
auto a = queens[i];
auto b = queens[j];
int x = a.first - b.first;
int y = a.second - b.second;
if (x == 0 || y == 0 || y == x || y == -x) {
return false;
}
}
}
return true;
}
void branch(std::vector<std::pair<int, int>> queens, int y, int n) {
if (y != n) {
for (int x = 0; x < n; x++) {
queens.push_back({ x, y });
if (safeSol(queens)) {
if (y == n - 1) {
solve.push_back(queens);
} else {
branch(queens, y + 1, n);
}
}
queens.pop_back();
}
}
}
std::vector<std::string> convert(const std::vector<std::pair<int, int>>& queens, int n) {
std::vector<std::string> s(n, std::string(n, '.'));
for (const auto& queen : queens) {
s[queen.second][queen.first] = 'Q';
}
return s;
}
int totalNQueens(int n) {
std::vector<std::pair<int, int>> q;
branch(q, 0, n);
return solve.size();
}
};
62. Unique Paths
tags:math
class Solution {
public:
int uniquePaths(int m, int n) {
if(m<n){
int temp=m;
m=n;
n=temp;
}
double ans=1;
// (m+n-2)!/(n-1)!/(m-1)!
for(int i=m;i<=m+n-2;i++)
ans*=i;
for(int i=1;i<n;i++)
ans/=i;
return ans;
}
};
71. Simplify Path
tags:stack
class Solution {
public:
string simplifyPath(string path) {
vector<string> p;
int n = path.size();
int i = 0;
bool slash = false;
string temp;
while (i < n) {
if (path[i] == '/') {
i++;
slash=true;
continue;
}
if (slash ==true) {
if (temp == ".." &&!p.empty())
p.pop_back();
else if (temp != "." && temp!="" &&temp != "..")
p.push_back(temp);
temp = "";
slash = false;
}
temp.push_back(path[i]);
i++;
}
if (temp == ".." && !p.empty())
p.pop_back();
else if (!temp.empty() &&temp != "." && temp!="..")
p.push_back(temp);
string ans = "/";
for (string &v : p)
ans += v + "/";
if (ans.size() > 1) {
ans.pop_back(); // Fix: Remove the trailing '/'
}
return ans;
}
};
73. Set Matrix Zeroes
tags:dp
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
//row dp
vector<bool> r=vector<bool>(matrix.size(),false);
//column dp
vector<bool> c=vector<bool>(matrix[0].size(),false);
for(int i =0;i<matrix.size();i++){
for(int j =0;j<matrix[0].size();j++){
if(matrix[i][j]==0 ){
r[i]=true;
c[j]=true;
}
}
}
for(int i =0;i<matrix.size();i++){
for(int j =0;j<matrix[0].size();j++){
if(r[i] || c[j])
matrix[i][j]=0;
}
}
}
};
77. Combinations
tags:queue
class Solution {
public:
vector<vector<int>> combine(int n, int k) {
vector<vector<int>>c;
std::queue<pair<int,vector<int>>> q;
for(int i =1;i<=n;i++)
q.push( {i, {i}} );
while(!q.empty()){
auto [id,v]=q.front();
q.pop();
if(v.size()==k)
c.push_back(v);
else{
for(int i=id+1;i<=n;i++){
auto vp=v;
vp.push_back(i);
q.push({i,vp});
}
}
}
return c;
}
};
78. Subsets
tags:binary
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
//2^n == (1 << nums.size())
vector<vector<int>> re((1 << nums.size()), vector<int>{});
for(int i = 0;i < re.size();++i){
for(int j = 0;j < nums.size();++j){
// use i in bin as combination
if(i & (1 << j))
re[i].push_back(nums[j]);
}
}
return re;
}
};
79. Word Search
tags:dfs
class Solution {
public:
int m,n;
vector<vector<bool>> s;
string w;
bool dfs(vector<vector<char>>& b,int x,int y,int i,int len){
if(i==len)
return true;
s[y][x]=false;
//right
if(x+1<n && s[y][x+1] && b[y][x+1]==w[i] &&dfs(b,x+1,y,i+1,len)==true)
return true;
if(x-1>=0 && s[y][x-1] && b[y][x-1]==w[i] &&dfs(b,x-1,y,i+1,len)==true)
return true;
if(y+1<m && s[y+1][x] && b[y+1][x]==w[i] &&dfs(b,x,y+1,i+1,len)==true)
return true;
if(y-1>=0 && s[y-1][x] && b[y-1][x]==w[i] &&dfs(b,x,y-1,i+1,len)==true)
return true;
s[y][x]=true;
return false;
}
bool exist(vector<vector<char>>& board, string word) {
m=board.size();
n=board[0].size();
w=word;
s=vector<vector<bool>>(m,vector<bool>(n,true));
for(int i=0;i<board.size();i++)
for(int j=0;j<board[0].size();j++)
if(board[i][j]==word[0] && dfs(board,j,i,1,word.size())==true)
return true;
return false;
}
};
91. Decode Ways
tags:dfs
class Solution {
public:
int ans=0;
map<int,int> dp;
int dfs(string& s, int id){
if(id<s.size() ){
//beened
if(dp.find(id)!=dp.end())
return dp[id];
int c=0;
// not zero
if(s[id]!='0'){
c+=dfs(s,id+1);
//have 2 digite and not over 26
if(id<s.size()-1 && (s[id]-'0'<2 || (s[id]-'0'==2 &&s[id+1]-'0'<7 ) ))
c+=dfs(s,id+2);
dp[id]=c;
}
return c;
}
return 1;
}
int numDecodings(string s) {
return dfs(s,0);
}
};
98. Validate Binary Search Tree
tags:dfs inorder
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* ** **TreeNode()****: val(0), left(nullptr), right(nullptr) {}
* ** **TreeNode(int x)****: val(x), left(nullptr), right(nullptr) {}
* ** **TreeNode(int x, TreeNode *left, TreeNode *right)****: val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int last=INT_MIN;
bool take=false;
//dfs in inorder check is vaild
bool dfs(TreeNode* n){
if(n!=nullptr){
//leaf node
if(n->right==n->left){
//if value smailer then last value then is not vaild
if( (n->val!=INT_MIN && last>=n->val) ||(take && n->val==INT_MIN ))
return false;
last=n->val;
take=true;
}
else{
//if left node is not vaild or the current node is not vaild then return false
if(!dfs(n->left) || (n->val!=INT_MIN && last>=n->val) ||(take && n->val==INT_MIN ))
return false;
last=n->val;
take=true;
if(!dfs(n->right))
return false;
}
}
return true;
}
bool isValidBST(TreeNode* root) {
return dfs(root) ;
}
};
120. Triangle
tags:dp
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
vector<vector<int>> dp;
int n=triangle.size();
dp.assign(n,vector<int>(n,INT_MAX));
dp[0][0]=triangle[0][0];
for(int i=1;i<n;i++){
//i 0
dp[i][0]=dp[i-1][0]+triangle[i][0];
for(int j=1;j<i;j++){
dp[i][j]=min(dp[i-1][j],dp[i-1][j-1])+triangle[i][j];
}
// i i
dp[i][i]=dp[i-1][i-1]+triangle[i][i];
}
int ans=INT_MAX;
for(auto &v:dp[n-1])
ans=min(v,ans);
return ans;
}
};
139. Word Break
tags:dp 2023/08/06
class Solution {
public:
int n =0;
set<string> dict;
map<int ,bool> dp;
bool f(string &s,int k){
if(dp.find(k)!=dp.end())
return dp[k];
//end
if(k==n)
return true;
//max lenght is 20
for(int i=1;i<20 && k+i<=n ;i++){
if(dict.count(s.substr(k,i))!=0 && f(s,i+k) ){
dp[i+k]=true;
return true;
}
}
dp[k]=false;
return false;
}
bool wordBreak(string s, vector<string>& wordDict) {
n=s.size();
for(auto &word:wordDict)
dict.insert(word);
return f(s,0);
}
};
148. Sort List
tags:linklist merge sort
for linklist merge two sorted list only need to change one pointer
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ** **ListNode()****: val(0), next(nullptr) {}
* ** **ListNode(int x)****: val(x), next(nullptr) {}
* ** **ListNode(int x, ListNode *next)****: val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* merge(ListNode* l ,ListNode* r ){
auto h=new ListNode(0);
auto v=h;
while(l!=nullptr&&r!=nullptr){
if(l->val <= r->val){
h->next=l;
l=l->next;
}
else{
h->next=r;
r=r->next;
}
h=h->next;
}
if(l!=nullptr)
h->next=l;
if(r!=nullptr)
h->next=r;
v=v->next;
// delete(h);
return v;
}
ListNode* sortList(ListNode* head) {
if(head==nullptr || head->next==nullptr)return head;
auto f =head;
auto s =head;
ListNode* tail=nullptr;
while( f !=nullptr &&f->next !=nullptr ){
tail=s;
s =s->next;
f=f->next->next;
}
tail->next=nullptr;
auto l=sortList(head);
auto r=sortList(s);
// return merge(l,r);
return merge(l,r);
}
};
198. House Robber
tags:dp
M(k) = money at the kth house
P(0) = 0
P(1) = M(1)
P(k) = max(P(k−2) + M(k), P(k−1))
class Solution {
public:
int rob(vector<int>& nums) {
int n=nums.size();
vector<int> dp=vector<int>(n,0);
for(int i =n-1;i>=0;i--){
if(i==n-1)
dp[i]=nums[i];
else if(i==n-2)
dp[i]=max(nums[i],dp[i+1]);
else
dp[i]=max(nums[i]+dp[i+2],dp[i+1]);
}
return dp[0];
}
};
279. Perfect Squares
tags:dp
class Solution {
public:
map<int,int>dp;
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0]=0;
for(int i=1;i<=n;i++){
for(int j=1;j*j<=i;j++){
dp[i]=min(dp[i],1+dp[i-j*j]);
}
}
return dp[n];
}
};
322. Coin Change
tags: dp
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp (amount+1,INT_MAX);
if(amount==0)
return 0;
dp[0]=0;
sort(begin(coins), end(coins));
for(int i=0;i<=amount;i++){
for(auto &v:coins){
if(v>amount)
break;
if(dp[i]!=INT_MAX && v+i<=amount )
dp[i+v]=min(dp[i]+1,dp[i+v]);
}
}
return dp[amount]!=INT_MAX?dp[amount]:-1;
}
};
341. Flatten Nested List Iterator
tags: queue
/**
* // This is the interface that allows for creating nested lists.
* // You should not implement it, or speculate about its implementation
* class NestedInteger {
* **public**:
* // Return true if this NestedInteger holds a single integer, rather than a nested list.
* bool isInteger() const;
*
* // Return the single integer that this NestedInteger holds, if it holds a single integer
* // The result is undefined if this NestedInteger holds a nested list
* int getInteger() const;
*
* // Return the nested list that this NestedInteger holds, if it holds a nested list
* // The result is undefined if this NestedInteger holds a single integer
* const vector<NestedInteger> &getList() const;
* };
*/
class NestedIterator {
public:
// vector<NestedInteger> l;
vector <int > dqv;
int id=0;
NestedIterator(vector<NestedInteger> nestedList) {
deque <NestedInteger > dq;
for (auto &i : nestedList)
dq.push_back( i);
while(!dq.empty()){
auto v=dq.front();
dq.pop_front();
if(v.isInteger())
dqv.emplace_back(v.getInteger());
for(int i =v.getList().size()-1;i>=0;i--)
dq.push_front(v.getList()[i]);
}
}
int next() {
return dqv[id++];
}
bool hasNext() {
return id<dqv.size();
}
};
/**
* **Your NestedIterator object will be instantiated and called as such**:
* NestedIterator i(nestedList);
* while (i.hasNext()) cout << i.next();
*/
416. Partition Equal Subset Sum
tags:dp
class Solution {
public:
bool subsetk(vector<int> &x,int sum,int n){
bool dp[n+1][sum+1];
//init
for(int i =0;i<=sum;i++)
dp[0][i]=false;
//have reach 0
for(int i =0;i<=n;i++)
dp[i][0]=true;
for(int i=1;i<=n;i++){
for(int j=1;j<=sum;j++){
if(x[i-1]<=j)
dp[i][j]=dp[i-1][j] || dp[i-1][j-x[i-1]];
else
dp[i][j]=dp[i-1][j];
}
}
return dp[n][sum];
}
bool canPartition(vector<int>& nums) {
list<int> l;
int sum=0;
for(auto &v: nums)
sum+=v;
if(sum &1 )
return false;
return subsetk(nums,sum/2,nums.size());
}
};
712. Minimum ASCII Delete Sum for Two Strings
tags:dp Longest Common Subsequence
class Solution {
public:
int minC=INT_MAX;
vector<vector<int>> dp;
int lcs(int i,int j,string&s1,string&s2 ){
if(dp[i][j]!=INT_MAX)return dp[i][j];
if(i==s1.size() && j==s2.size()) return dp[i][j]=0;
if(i==s1.size())return dp[i][j]=s2[j]+lcs(i,j+1,s1,s2);
if(j==s2.size())return dp[i][j]=s1[i]+lcs(i+1,j,s1,s2);
int sum;
if(s1[i]==s2[j])
sum=lcs(i+1,j+1,s1,s2);
else
sum=min( lcs(i+1,j,s1,s2)+s1[i],lcs(i,j+1,s1,s2)+s2[j]);
return dp[i][j]=sum;
}
int minimumDeleteSum(string s1, string s2) {
dp.assign(s1.size()+1,vector(s2.size()+1,INT_MAX));
return lcs(0,0,s1,s2);
}
};
1143. Longest Common Subsequence
tags:dp
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int>> dp;
int n=text1.size(),m=text2.size();
dp.assign(n+1,vector(m+1,0));
for(int i =1;i<n+1;i++){
for(int j =1;j<m+1;j++){
if(text1[i-1]==text2[j-1]){
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
}
}
}
return dp[n][m];
}
};
1218. Longest Arithmetic Subsequence of Given Difference
tags:dp
class Solution {
public:
unordered_map<int,int> dp;
int longestSubsequence(vector<int>& arr, int difference) {
int maxV=1;
int n=arr.size();
for(int &v:arr){
if(dp.find(v-difference)!=dp.end())
dp[v]=dp[v-difference]+1;
else
dp[v]=1;
maxV=max(maxV,dp[v]);
}
return maxV;
}
};
1705. Maximum Number of Eaten Apples
tags:priorty queue
alway take the apple that is closest to the Validity limte
class Solution {
public:
int eatenApples(vector<int>& apples, vector<int>& days) {
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;
int i=0;
int number = 0;
while (!pq.empty() || i < days.size()) {
while (!pq.empty()&&pq.top().first<=i)
pq.pop();
if (i < days.size() && apples[i] != 0) {
pq.push({i+days[i],apples[i]});
}
if(!pq.empty()){
auto take=pq.top();
pq.pop();
if(--take.second>0){
pq.push(take);
}
number++;
}
i++;
}
return number;
}
};
2024. Maximize the Confusion of an Exam
tags:sliding window
maintain the range that fit the requirement
class Solution {
public:
int maxConsecutiveAnswers(string answerKey, int k) {
int left =0;
int right=0;
int n =answerKey.size();
int t=0,f=0;
int ans=INT_MIN;
int minC=0;
while(left <answerKey.size()){
minC=min(t,f);
while(minC<=k &&right<n){
ans=max(ans,right-left);
if(answerKey[right]=='T')
t++;
else
f++;
minC=min(t,f);
right++;
if(minC<=k)
ans=max(ans,right-left);
}
if(right==n)
ans=max(ans,right-left-1);
if(answerKey[left++]=='T')
t--;
else
f--;
}
return ans;
return ans==INT_MIN?n:ans;
}
};
2305. Fair Distribution of Cookies
tags:dfs
dfs find every possible
class Solution {
public:
int minMax=INT_MAX;
vector<int>c;
int k=0;
int t=0;
void dfs(vector<int> &status,int n){
if(n<t){
auto v=c[n++];
for(int i=0;i<k;i++){
status[i]+=v;
dfs(status,n);
status[i]-=v;
}
}else{
int maxV=INT_MIN;
for(auto i:status)
maxV=max(i,maxV);
minMax=min(minMax,maxV);
}
}
int distributeCookies(vector<int>& cookies, int kk) {
c.insert(c.begin(),cookies.begin(),cookies.end());
t=c.size();
k=kk;
vector<int> temp(k,0);
dfs(temp,0);
return minMax;
}
};
machine-learing
resnet
residual block(skip-connection)
transformer
attention
self attention
transformer encoder
cross attention
transformer decoder
causal attention
CLIP
class Clip(nn.Module):
def __init__(self,motion_dim=75,music_dim=438,feature_dim=256):
super(Clip, self).__init__()
self.motion_encoder = MotionEncoder(input_channels=motion_dim,feature_dim=feature_dim)
self.music_encoder = MusicEncoder(input_channels=music_dim,feature_dim=feature_dim)
self.motion_project = nn.Linear(feature_dim, feature_dim)
self.music_project = nn.Linear(feature_dim, feature_dim)
self.temperature = nn.Parameter(torch.tensor(1.0))
self.criterion = nn.CrossEntropyLoss()
def forward(self, motion:Tensor, music:Tensor):
assert motion.shape[1] == music.shape[1]
b,s,c= motion.shape
motion_features = self.motion_encoder(motion)
music_features = self.music_encoder(music)
motion_features =F.normalize( self.motion_project(motion_features),p=2,dim=-1)
music_features = F.normalize( self.music_project(music_features),p=2,dim=-1)
# relation=(motion_features@music_features.T)*(1.0 / math.sqrt(c))
# batch matrix multiplication and .mT is batch transpose matrix
logits=torch.bmm(motion_features,music_features.mT)*self.temperature
labels=torch.arange(s).repeat(b,1).to(motion.device)
loss_motion = self.criterion(logits, labels)
loss_music = self.criterion(logits.mT, labels)
loss=(loss_motion+loss_music)/2
return (motion_features,music_features),(loss,loss_motion,loss_music)
CAN(GAN base)
AE

VAE

reparameterization trick
Assuming the distribution of the output is a Gaussian distribution, the model only predicts the mean () and std (). We then sample the latent variable from this Gaussian distribution. The sample latent distribution parameters should match the true distribution, which is enforced using the KL divergence.
VAE loss
Evidence Lower Bound (ELBO)
We want replace with since we dont have GT of
base on difference condition KL divergence can simplify to difference term
- Variational Inference
- Importance Sampling to ELBO
- Variational EM
refs
VQVAE(d-vae)
Variational Autoencoder (Kingma & Welling, 2014)
quantise bottleneck

- random init centroids
- find the nearest centroids of each unquantise vector
- if quantise have low usage then random init a new centroids
- calculate average center of unquantise vector
- Exponential Moving Average Update between new centroid and old centroid
loss
- VQ loss: The L2 error between the embedding space and the encoder outputs.
- Commitment loss: A measure to encourage the encoder output to stay close to the embedding space and to prevent it from fluctuating too frequently from one code vector to another.
- where is the
stop_gradientoperator.
CVAE
reinforce learning
actor-critic
origin
- : state at time t
- : value function predict reward with
- : action function return action probability base on
- top1: select the action with max probability
- : reward function input a sequence of action out float
- advantages value: if the can get more reward then positive value else negative value
with Temporal Difference error(TD-error)
- Hope can predict reward that may get in future with proportion
- note: you should add
stop gradientto (aka detach in pytorch)
AE
VAE
reparameterization trick
Assuming the distribution of the output is a Gaussian distribution, the model only predicts the mean () and std (). We then sample the latent variable from this Gaussian distribution. The sample latent distribution parameters should match the true distribution, which is enforced using the KL divergence.
VAE loss
Evidence Lower Bound (ELBO)
We want replace with since we dont have GT of
base on difference condition KL divergence can simplify to difference term
- Variational Inference
- Importance Sampling to ELBO
- Variational EM
refs
VQVAE(d-vae)
Variational Autoencoder (Kingma & Welling, 2014)
quantise bottleneck
- random init centroids
- find the nearest centroids of each unquantise vector
- if quantise have low usage then random init a new centroids
- calculate average center of unquantise vector
- Exponential Moving Average Update between new centroid and old centroid
loss
- VQ loss: The L2 error between the embedding space and the encoder outputs.
- Commitment loss: A measure to encourage the encoder output to stay close to the embedding space and to prevent it from fluctuating too frequently from one code vector to another.
- where is the
stop_gradientoperator.
CVAE
reinforce learning
actor-critic
origin
- : state at time t
- : value function predict reward with
- : action function return action probability base on
- top1: select the action with max probability
- : reward function input a sequence of action out float
- advantages value: if the can get more reward then positive value else negative value
with Temporal Difference error(TD-error)
- Hope can predict reward that may get in future with proportion
- note: you should add
stop gradientto (aka detach in pytorch)
transformer
attention
self attention
transformer encoder
cross attention
transformer decoder
causal attention
CLIP
class Clip(nn.Module):
def __init__(self,motion_dim=75,music_dim=438,feature_dim=256):
super(Clip, self).__init__()
self.motion_encoder = MotionEncoder(input_channels=motion_dim,feature_dim=feature_dim)
self.music_encoder = MusicEncoder(input_channels=music_dim,feature_dim=feature_dim)
self.motion_project = nn.Linear(feature_dim, feature_dim)
self.music_project = nn.Linear(feature_dim, feature_dim)
self.temperature = nn.Parameter(torch.tensor(1.0))
self.criterion = nn.CrossEntropyLoss()
def forward(self, motion:Tensor, music:Tensor):
assert motion.shape[1] == music.shape[1]
b,s,c= motion.shape
motion_features = self.motion_encoder(motion)
music_features = self.music_encoder(music)
motion_features =F.normalize( self.motion_project(motion_features),p=2,dim=-1)
music_features = F.normalize( self.music_project(music_features),p=2,dim=-1)
# relation=(motion_features@music_features.T)*(1.0 / math.sqrt(c))
# batch matrix multiplication and .mT is batch transpose matrix
logits=torch.bmm(motion_features,music_features.mT)*self.temperature
labels=torch.arange(s).repeat(b,1).to(motion.device)
loss_motion = self.criterion(logits, labels)
loss_music = self.criterion(logits.mT, labels)
loss=(loss_motion+loss_music)/2
return (motion_features,music_features),(loss,loss_motion,loss_music)
GAN
WGAN
WGAN-GP
Lipschitz continuous function
1-Lipschitz continuity
mean value theorem
if is differentiable function then
gradient penalty
by let close to 1 the function can satisfy 1-Lipschitz requires
# https://github.com/Lornatang/WassersteinGAN_GP-PyTorch/blob/f2e2659089a4fe4cb7e1c4edeb5c5b9912e9c348/wgangp_pytorch/utils.py#L39
def calculate_gradient_penalty(model, real_images, fake_images, device,use_refiner):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake data
alpha = torch.randn((real_images.size(0), 1, 1 , 1), device=device)
# Get random interpolation between real and fake data
interpolates = (alpha * real_images + ((1 - alpha) * fake_images)).requires_grad_(True)
_, interpolates_real = model(interpolates,return_feature=False,use_refiner=use_refiner)
grad_outputs = torch.ones_like(interpolates_real, device=device)
# Get gradient w.r.t. interpolates
gradients = torch.autograd.grad(
outputs=interpolates_real,
inputs=interpolates,
grad_outputs=grad_outputs,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.reshape(gradients.size(0), -1)
gradient_penalty = torch.mean((gradients.norm(2, dim=1) - 1) ** 2)
return gradient_penalty
CAN(GAN base)
CBMC(C Bounded Model Checking)
model checking is a method for checking whether a finite-state model of a system meets a given specification.
CBMC overview

program into a control flow graph

program
if ( (0 <= t) && (t <= 79) )
{
switch ( t / 20 )
{
case 0:
TEMP2 = ( (B AND C) OR (~B AND D) );
break;
case 1:
TEMP2 = ( (B XOR C XOR D) );
break;
case 2:
TEMP2 = ( (B AND C) OR (B AND D) OR (C AND D) );
break;
case 3:
TEMP2 = ( B XOR C XOR D );
break;
default:
}
assert(TEMP2>0);
}
code flow graph

Linear temporal logic
- Linear temporal logic
- G for always (globally)
- F for finally
- R for release
- W for weak until
- M for mighty release
- Computation tree logic
- A – All
- E – Exists
- X - NeXt

Goal: check properties of the form AG p, satisfy assertions.
SAT solver
https://www.inf.ufpr.br/dpasqualin/d3-dpll/ SAT solver will find instance that satisfy all cases
But SAT only can solve pure boolean satisfiability problem
is boolean but is INT32 or INT8 how to convert it to pure boolean probleam
convert code to conjunctive normal form for SAT solver

SAT will try to find the counter of
we can check is exist counter example of the form AG p
convert to pure boolean
digital logic

loop
while(cond){
a++;
assert(a<0);
}
unrolling
bounded model checking bounded how deep we can unrolling
if(cond){
a++;
assert(a<0);
if(cond){
a++;
assert(a<0);
if(cond){
a++;
assert(a<0);
if(cond){
a++;
assert(a<0);
....
}
}
}
}
unrolling optimization

pointer bound
int n;
int ∗p;
p=malloc(sizeof(int)∗5);
p[n]=100;
int n;
int ∗p;
p=malloc(sizeof(int)∗5);
assert(0<=n && n<5);
p[n]=100;
code example overflow
void f00 (int x, int y, int z) {
if (x < y) {
int firstSum = x + z;
int secondSum = y + z;
assert(firstSum < secondSum);
}
}
example.c function f00
[f00.assertion.1] line 16 assertion firstSum < secondSum: FAILURE
Trace for f00.assertion.1:
↳ example.c:12 f00(-1275228454, 1113655513, -1157894487)
14: firstSum=1861844355 (01101110 11111001 01111101 10000011)
15: secondSum=-44238974 (11111101 01011100 11110111 10000010)
Violated property:
file example.c function f00 line 16 thread 0
assertion firstSum < secondSum
firstSum < secondSum
code example pointer
void f15 (int x, int y) {
int a[5]={1,2,3,4,5};
int *b= (int *)malloc(5 * sizeof(int));
for(int i=0;i<5;i++)
b[i]=i;
int *p=a;
if(x==1 && y==1){
// p=b+1;
p=&b[1];
p[4]=5;
}
for(int i=0;i<5;i++){
assert(a[i] == p[i]);
}
free(b);
}
code example pointer
Trace for f15.pointer_dereference.12:
↳ example.c:143 f15(1, 1)
144: a={ 1, 2, 3, 4, 5 } ({ 00000000 00000000 00000000 00000001, 00000000 00000000 00000000 00000010, 00000000 00000000 00000000 00000011, 00000000 00000000 00000000 00000100, 00000000 00000000 00000000 00000101 })
144: a[0l]=1 (00000000 00000000 00000000 00000001)
144: a[1l]=2 (00000000 00000000 00000000 00000010)
144: a[2l]=3 (00000000 00000000 00000000 00000011)
144: a[3l]=4 (00000000 00000000 00000000 00000100)
144: a[4l]=5 (00000000 00000000 00000000 00000101)
↳ example.c:146 malloc(sizeof(signed int) * 5ul /*20ul*/ )
12: dynamic_object1[0l]=0 (00000000 00000000 00000000 00000000)
12: dynamic_object1[1l]=0 (00000000 00000000 00000000 00000000)
12: dynamic_object1[2l]=0 (00000000 00000000 00000000 00000000)
12: dynamic_object1[3l]=0 (00000000 00000000 00000000 00000000)
12: dynamic_object1[4l]=0 (00000000 00000000 00000000 00000000)
146: b=dynamic_object1 (00000010 00000000 00000000 00000000 00000000 00000000 00000000 00000000)
147: i=0 (00000000 00000000 00000000 00000000)
148: dynamic_object1[0l]=0 (00000000 00000000 00000000 00000000)
147: i=1 (00000000 00000000 00000000 00000001)
148: dynamic_object1[1l]=1 (00000000 00000000 00000000 00000001)
147: i=2 (00000000 00000000 00000000 00000010)
148: dynamic_object1[2l]=2 (00000000 00000000 00000000 00000010)
147: i=3 (00000000 00000000 00000000 00000011)
148: dynamic_object1[3l]=3 (00000000 00000000 00000000 00000011)
147: i=4 (00000000 00000000 00000000 00000100)
148: dynamic_object1[4l]=4 (00000000 00000000 00000000 00000100)
147: i=5 (00000000 00000000 00000000 00000101)
150: p=((signed int *)NULL) (00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000)
151: p=a!0@1 (00000011 00000000 00000000 00000000 00000000 00000000 00000000 00000000)
155: p=dynamic_object1 + 1l (00000010 00000000 00000000 00000000 00000000 00000000 00000000 00000100)
Violated property:
file example.c function f15 line 156 thread 0
dereference failure: pointer outside dynamic object bounds in p[(signed long int)4]
16l + POINTER_OFFSET(p) >= 0l && __CPROVER_malloc_size >= 20ul + (unsigned long int)POINTER_OFFSET(p) || !(POINTER_OBJECT(p) == POINTER_OBJECT(__CPROVER_malloc_object))
code example multiple
void f14 (int x, int y) {
int a = x;
int b = y;
assert(a*b == x*y);
}
code example multiple MiniSAT
CBMC version 5.12 (cbmc-5.12) 64-bit x86_64 linux
Parsing example.c
Converting
Type-checking example
Generating GOTO Program
Adding CPROVER library (x86_64)
Removal of function pointers and virtual functions
Generic Property Instrumentation
Removing unused functions
Dropping 14 of 17 functions (3 used)
Performing a reachability slice
Running with 8 object bits, 56 offset bits (default)
Starting Bounded Model Checking
size of program expression: 47 steps
simple slicing removed 4 assignments
Generated 2 VCC(s), 1 remaining after simplification
Passing problem to propositional reduction
converting SSA
Running propositional reduction
Post-processing
Solving with MiniSAT 2.2.1 with simplifier
3817 variables, 18930 clauses
SAT checker: instance is UNSATISFIABLE
Runtime decision procedure: 477.908s
** Results:
function __CPROVER__start
[__CPROVER__start.memory-leak.1] dynamically allocated memory never freed in __CPROVER_memory_leak == NULL: SUCCESS
example.c function f14
[f14.assertion.1] line 140 assertion a*b == x*y: SUCCESS
** 0 of 2 failed (1 iterations)
VERIFICATION SUCCESSFUL
code example multiple Z3
CBMC version 5.12 (cbmc-5.12) 64-bit x86_64 linux
Parsing example.c
Converting
Type-checking example
Generating GOTO Program
Adding CPROVER library (x86_64)
Removal of function pointers and virtual functions
Generic Property Instrumentation
Removing unused functions
Dropping 15 of 18 functions (3 used)
Performing a reachability slice
Running with 8 object bits, 56 offset bits (default)
Starting Bounded Model Checking
size of program expression: 47 steps
simple slicing removed 4 assignments
Generated 2 VCC(s), 1 remaining after simplification
Passing problem to SMT2 QF_AUFBV using Z3
converting SSA
Running SMT2 QF_AUFBV using Z3
Runtime decision procedure: 0.00870986s
** Results:
function __CPROVER__start
[__CPROVER__start.memory-leak.1] dynamically allocated memory never freed in __CPROVER_memory_leak == NULL: SUCCESS
example.c function f14
[f14.assertion.1] line 140 assertion a*b == x*y: SUCCESS
** 0 of 2 failed (1 iterations)
VERIFICATION SUCCESSFUL
SPIN
SPIN
- promela language
- deadlock deletction

promela language


two process FSM
the state that is not final state but have no next state is the deadlock state
convert property check to LTL expression

alot of work are try reduce computation to save time
summary
- use interactive and random simulations get the all reachable states and transction
- use the states and transction build finite-state machine
- check the is any counter example of assert
- property check to LTL to check all the reachable state is fit the property
ref
- https://www.cprover.org/cbmc/doc/cbmc-slides.pdf
- https://spinroot.com/spin/Doc/Spin_tutorial_2004.pdf
- https://www.cs.cmu.edu/~aldrich/courses/654-sp05/handouts/model-checking-5.pdf
NERF model
model genera
HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion
overfit the MLP to describe the 3d mesh then use the diffustion model to lean the associate of weight、baisand the string
training time
3-layer 128-dim MLPs contain ≈ 36k parameters, which are flattened and tokenized for diffusion. We use an Adam optimizer with batch size 32 and initial learning rate of , which is reduced by 20% every 200 epochs. We train for ≈ 4000 epochs until convergence, which takes ≈ 4 days on a single A6000 GPU
GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
use GAN and NERF to ganerative the 3D model
generator : input direaction and position and style latent space vector return color and density;
defector: input the image that render by volume rendering by genertor and real image predict loss;
nvdiffrec
use instant-nerf as nerf base and use DMTet to reconstruct the 3D mesh. The render image by 3D mesh and neural general PBR texture compare to the origin sample .
NeRFNeR:Neural Radiance Fields with Reflections
link use 2 mlp the reflection map and surface color;
mics
LERF: Language Embedded Radiance Fields
CLIP
decode text or image to the same latent space
Multiscale CLIP Preprocessin
slice traing image to diffrent size of image and use as ground truth
LERF
input :image
output :rgb、density 、DINO feature、CLIP feature
By find cosine similarity the input text CLIP featureand the LERF predict CLIP feature can show the connection between the text and NERF scene;
operating system
tags: software hardware system
Chapter 1: Computer System
Structure

One or more CPUs, device controllers connect through common bus providing access to shared memory

- Process Management
- Creating and deleting both user and system processes
- Suspending and resuming processes
- Providing mechanisms for process synchronization
- Providing mechanisms for process communication
- Providing mechanisms for deadlock handlin
- Memory Management
- Von Neumann architecture
- To execute a program, all (or part) of the instructions must be in memory
- All (or part) of the data that is needed by the program must be in memory
- Allocating and deallocating memory space as needed
- Keeping track of which parts of memory are currently being used and by whom
- Deciding which processes (or parts thereof) and data to move into and out of memory
- Von Neumann architecture
- file system management
- Abstracts physical properties to logical storage unit - file
- Access control on most systems to determine who can access what
- Mass-Storage Management
- mounting and unmounting
- fire-space management
- storage allocation
- disk scheduling
- partitioning
- protection
- caching management
- Faster storage (cache)
- mportant principle, performed at many levels in a computer (in hardware, operating system, software)
- I/O Subsystem
- buffering(storing data temporarily while it is being transferred)
- caching(storing part of data in faster storage for performance)
- spooling
operation
- I/O is from the device to local buffer of controller
- CPU moves data from/to main memory to/from local buffers
- Device controller informs CPU that it has finished its operation by causing an interrupt
interrupt
- software-generated interrupt :execption
- Modern OS is interrupt-driven
- Interrupt architecture must save the address of the interrupted instruction
Interrupt Handling
- The OS preserves the state of the CPU by storing the registers and the program counter
- type of interrupt
- polling
- vectored

I/O
handling I/O
- Synchronous: After I/O starts, control returns to user program only upon I/O completion
- wait instruction idles the cpu until the next interrupt
- wait loop
- Asynchronous: After I/O starts, control returns to user program without waiting for I/O completion
- system call:request to the OS to allow user to wait for I/O completion
storage structure
- main memory
- cpu can access directly
- Dynamic Random-access Memory (DRAM)
- Typically volatile
- HDD
- Non-volatile memory (NVM)

Direct Memory Access(DMA)

- Used for high-speed I/O devices able to transmit information at close to memory speeds
- Device controller transfers blocks of data from buffer storage directly to main memory without CPU intervention
- Only one interrupt is generated per block, rather than one interrupt per byte
Symmetric Multiprocessing Architecture
| Dual-Core Design | Non-Uniform Memory Access System |
|---|---|
 |  |
Virtualization
have different kernel

cloud computing

- Software as a Service (SaaS)
- one or more applications available via the Internet (i.e., word processor)
- Platform as a Service (PaaS)
- software stack ready for application use via the Internet (i.e., a database server)
- Infrastructure as a Service (IaaS)
- servers or storage available over Internet (i.e., storage available for backup use)
Kernel Data Structures

Chapter 2: Operating-System Service
System Calls
- Programming interface to the services provided by the OS
- Typically written in a high-level language (C or C++)
- Mostly accessed by programs via a high-level Application Programming Interface (API) rather than direct system call
- System Call Parameter Passing
- pushed, onto the stack by the program and popped off the stack by the OS

- pushed, onto the stack by the program and popped off the stack by the OS
Types of System Calls
- Process control
- create process, terminate process
- end, abort
- load, execute
- get process attributes, set process attributes
- wait for time
- wait event, signal event
- allocate and free memory
- Dump memory if error
- Debugger for determining bugs, single step execution
- Locks for managing access to shared data between
- File management
- create file, delete file
- open, close file
- read, write, reposition
- get and set file attributes
- Device management
- request device, release device
- read, write, reposition
- get device attributes, set device attributes
- logically attach or detach devices processes
- Information maintenance
- get time or date, set time or date
- get system data, set system data
- get and set process, file, or device attributes
- Communications
- create, delete communication connection
- send, receive messages if message passing model to host name or process name
- From client to server
- Shared-memory model create and gain access to memory regions
- transfer status information
- attach and detach remote devices

program stack

Linker and Loader
- Source code compiled into object files designed to be loaded into any physical memory location – relocatable object file
- Linker combines these into single binary executable file
- Also brings in libraries
- Modern general purpose systems don’t link libraries into executables
- Rather, dynamically linked libraries (in Windows, DLLs) are loaded as needed, shared by all that use the same version of that same library (loaded once

Operating System Structure
- Simple structure
- Monolithic Structure More
- Microkernel
- Layered
- Hybrid
Traditional UNIX System Structure
- UNIX:
- limited by hardware functionality, the original UNIX OS had limited structuring
- Consists of everything below the system-call interface and above the physical hardware
- Provides the file system, CPU scheduling, memory management, and other OS functions; a large number of functions for one level

Linux System Structure
Monolithic plus modular design

Microkernels
- Moves as much from the kernel into user space
- Mach is an example of microkernel
- Mac OS X kernel (Darwin) partly based on Mach
- Benefits:
- Easier to extend a microkernel
- Easier to port the OS to new architectures
- More reliable (less code is running in kernel mode)
- More secure
- Detriments:
- Performance overhead of user space to kernel space communication

Layered Approach
- The OS is divided into a number of layers (levels), each built on top of lower layers
- The bottom layer (layer 0), is the hardware
- the highest (layer N) is the user interface
- With modularity, layers are selected such that each uses functions (operations) and services of only lower- level layers
hybrid systems
- Apple Mac OS X hybrid, layered, Aqua UI plus Cocoa programming environment
| macOS iOS | darwin | android |
|---|---|---|
 |  |  |
System Boot
- When power initialized on system, execution starts at a fixed memory location
- Small piece of code
- bootstrap loader, BIOS, stored in ROM or EEPROM locates the kernel, loads it into memory, and starts it
- Modern systems replace BIOS with Unified Extensible Firmware Interface (UEFI)
- Common bootstrap loader, GRUB
tracing
- strace – trace system calls invoked by a process
- gdb – source-level debugger
- perf – collection of Linux performance tools
- tcpdump – collects network packets

Chapter 3: Processes
- The program code, also called text section
- Current activity including program counter, processor registers
- Stack containing temporary data
- Function parameters, return addresses, local variables
- Data section containing global variables
- Heap containing memory dynamically allocated during run time

process state
- new
- running
- waiting
- ready:the process is waiting to be assigned to a processor
- terminated

Process Scheduling
Process Control Block (PCB) or task control block)

scheduling
- Goal – Maximize CPU use, quickly switch
- processes onto CPU core
- Maintains scheduling queues of processes
- ready queue
- wait queue

context switch
- context-switch time is pure overhead; the system does no useful work while switching
- The more complex the OS and the PCB the longer the context switch
- Time dependent on hardware support
- Some hardware provides multiple sets of registers per CPU multiple contexts loaded at once

Operations on Processes

Inter Process Communication(IPC)
- shared memory
- message passing
IPC in Shared-Memory Systems
- An area of memory shared among the processes that wish to communicate
- The communication is under the control of the user processes not the OS
IPC in Message-Passing Systems
- Blocking is considered synchronous
- Non-blocking is considered asynchronous
Ordinary pipes
- unidirectional(single direction)
- cannot be accessed from outside the process that created it.
- Typically, a parent process creates a pipe and uses it to communicate with a child process that it created
named pipes
- Communication is bidirectional
- No parent-child relationship is necessary between the communicating processes
Client-Server Systems
| sockets | Remote Procedure Calls (RPC) |
|---|---|
 |  |
Chapter 4: Threads & Concurrency
Concurrency vs. Parallelism

Multicore Programming
- Data parallelism
- different data, same operation on each data
- Task parallelism
- different operation, same data
Amdahl’s Law

Multithreading Models
- Many-to-One
- One thread blocking causes all to block
- example
- solaris green threads
- GUN portable threads
- One-to-One
- More concurrency than many-to-one
- example
- windows
- linux
- Many-to-Many
- Windows with the ThreadFiber package
- two-level model
- mix Many-to-Many and One-To-One
| Many-to-One | ono-to-one | Many-to-Many | two-level model |
|---|---|---|---|
 |  |  |  |
Implicit threading
- Thread Pools
- Create a number of threads in a pool where they await work
- Fork-Join Parallelism
- OpenMP
- Grand Central Dispatch
- dispatch queues
- macOS,iOS
Chapter 5: CPU Scheduling
CPU scheduler
- CPU utilization
- keep the CPU as busy as possible
- Throughput
- of processes that complete their execution per time unit
- Turnaround time
- amount of time to execute a particular process
- turnaround time = completion time – arrival time
- Waiting time
- amount of time a process has been waiting in the ready queue
- waiting time = turnaround time – burst time
- Response time
- amount of time it takes from when a request was submitted until the first response is produce
- response time = start time – arrival time
CPU scheduling decisions may take place when a process:
- Switches from running to waiting state
- Switches from running to ready state
- Switches from waiting to ready
- Terminates
Preemptive
- preemptive
- can result in race conditions
- linux,windows,MacOS
- nonpreemptive
- only under circumstances 1 and 4
Dispatcher
- witching context
- Switching to user mode
- Jumping to the proper location in the user program to restart that program
Dispatch latency =time it take to stop one process and start another running
Scheduling Algorithm
- Max CPU utilization
- Max throughput
- Min turnaround time
- Min waiting time
- Min response time
Determining Length of Next CPU Burst
- exponential averaging

First- Come, First-Served(FCFS) Scheduling

- Convoy effect short process behind long process
- Consider one CPU-bound and many I/O-bound processes
Shortest-Job-First(SJF) Scheduling
- minimum average waiting time for a given set of processes
shortest-remaining-time-first(Preemptive SJF)
| process | arrival time | burst time |
|---|---|---|
| 0 | 8 | |
| 1 | 4 | |
| 2 | 9 | |
| 3 | 5 |

Round Robin (RR)
- Each process gets a small unit of CPU time (time quantum q), usually 10-100 milliseconds
- After this time has elapsed, the process is preempted and added to the end of the ready queue
- Typically, higher average turnaround than
SJF, but better response
| process | burst time |
|---|---|
| 8 | |
| 4 | |
| 9 |

Priority Scheduling
- The CPU is allocated to the process with the highest priority
SJFis priority scheduling where priority is the inverse of predicted next CPU burst time
| process | burst time | priority |
|---|---|---|
| 10 | 3 | |
| 1 | 1 | |
| 2 | 4 | |
| 1 | 5 | |
| 5 | 2 |

Priority Scheduling + Round-Robin
- Run the process with the highest priority
- Processes with the same priority run round-robin
| process | burst time | priority |
|---|---|---|
| 7 | 1 | |
| 5 | 2 | |
| 8 | 2 | |
| 4 | 3 | |
| 3 | 3 |

Multilevel Queue

Multiple-Processor Scheduling
- Multicore CPUs
- Multithreaded cores
- NUMA(non-uniform memory access) systems
- Heterogeneous multiprocessing
SMP
- Symmetric multiprocessing (SMP) is where each processor is self-scheduling
- (a) All threads may be in a common ready queue
- (b) Each processor may have its own private queue of threads
- keep all CPUs loaded for efficiency
- Load balancing
- attempts to keep workload evenly distributed
- push migration
- pushes task from overloaded CPU to other CPUs
- pull migration
- idle processors pulls waiting task from busy processor
- Load balancing
- processor affinity
- Soft affinity
- the OS attempts to keep a thread running on the same processor, but no guarantees
- Hard affinity
- allows a process to specify a set of processors it may run on
- Soft affinity

hyperthreading

real-time scheduling
- Real-Time system
- soft real-time system
- but no guarantee as to when tasks will be scheduled
- hard real-time system
- task must be serviced by its deadline
- soft real-time system
- latency
- Interrupt latency
- time of stop process to another process
- Dispatch latency
- take current process off CPU and switch to another CPU
- Interrupt latency
Earliest Deadline First Scheduling (EDF)
- Priorities are assigned according to deadlines:
- the earlier the deadline, the higher the priority
- the later the deadline, the lower the priority

Operating System Examples
linux scheduling
- Completely Fair Scheduler (CFS)
- CFS scheduler maintains per task virtual run time in variable vruntime
- To decide next task to run, scheduler picks task with lowest virtual run time
- Linux supports load balancing, but is also NUMA-aware
solaris scheduling
- priority-based scheduling
- Six classes available
- Time sharing (default) (TS)
- Interactive (IA)
- Real time (RT)
- System (SYS)
- Fair Share (FSS)
- Fixed priority (FP)

Chapter 6: Synchronization Tools
Race condition

critical sectionsegment of code- Process may be changing common variables, updating table, writing file, etc
- When one process in critical section, no other may be in its critical section
Critical-Section Problem
- Mutual Exclusion
- If process is executing in its critical section, then no other processes can be executing in their critical sections
- Progress
- if not process in critical section and have process want to enter critical section then have to let the process
- Bounded Waiting
- the time process wait to enter critical section have to limit(cant wait forever)
software solution
- cant avoid shared variable be override value by another process
- Entry section: disable interrupts
- Exit section: enable interrupts
part of Solution
-
Assume that the
loadandstoremachine-language instructions areatomic- Which cannot be interrupted
-
turnindicates whose turn it is to enter the critical section -
two process have enter critical section in turn

Peterson’s Solution
- Assume that the
loadandstoremachine-language instructions areatomic- Which cannot be interrupted
turnindicates whose turn it is to enter the critical sectionflagarray is used to indicate if a process is ready to enter the critical section- solve
critical section problem- Mutual exclusion
- progress
- bounded-waiting

Memory Barrier
- Memory models may be either:
- Strongly ordered – where a memory modification of one processor is immediately visible to all other processors
- Weakly ordered – where a memory modification of one processor may not be immediately visible to all other processors

Mutex Locks
- First acquire() a lock
- Then release() the lock
busy waiting- the process will be block and continuous check is lock
spinlockwhen is lock free will automatic let the waiting process know
semaphore
- wait()
- signal()
- Counting semaphore
- integer value can range over an unrestricted domain
- Binary semaphore
- integer value can range only between 0 and 1
- Same as a mutex lock
- Must guarantee that no two processes can execute the
wait()andsignal()on the same semaphore at the same time
Semaphore Implementation with no Busy waiting
- block()
- place the process invoking the operation on the appropriate waiting queue
- wakeup()
- remove one of processes in the waiting queue and place it in the ready queue
Synchronization Hardware
- Hardware instruction
- Atomic Swap()
- Test and Set()
- Atomic variables
Hardware instruction
Atomic variables
- atomic variable that provides atomic (uninterruptible) updates on basic data types such as integers and booleans
deadlock

- deadlock
- two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes
- Starvation
- indefinite blocking
- A process may never be removed from the semaphore queue in which it is suspended
- Priority Inversion
- Scheduling problem when lower-priority process holds a lock needed by higher-priority process
- Solved via priority-inheritance protocol
Chapter 7: Synchronization Examples
Problems of Synchronization
Most of the synchronization problems do not exist in functional languages
- Bounded-Buffer Problem (Producer-consumer problem)
- Readers and Writers Problem
- Dining-Philosophers Problem
OS
- windows
- spinlocks
- dispatcher object
- linux
- Atomic integers
- Mutex locks
- Spinlocks, Semaphores
- Reader-writer versions of both
- POSIX
- mutex locks
- semaphores
- named
- can be used by unrelated processes
- unnamed
- can be used only by threads in the same process
- named
- condition variable
Chapter 8: Deadlocks
Deadlock Characterization
- Mutual exclusion
- only one process at a time can use a resource
- Hold and wait
- a process holding at least one resource is waiting to acquire additional resources held by other processes
- No preemption
- a resource can be released only voluntarily by the process holding it, after that process has completed its task
- Circular wait
- there exists a set {P0, P1, …, Pn} of waiting processes such that:
Deadlocks Prevention
- mutual exclusion
- not required for sharable resources (e.g., read-only files); must hold for non-sharable resource
- hold and wait
- must guarantee that whenever a process requests a resource, it does not hold any other resources
- No Preemption
- If a process that is holding some resources requests another resource that cannot be immediately allocated to it, then all resources currently being held are released
- Circular Wai
- check is have circular wait or not
Deadlock Avoidance
- Cant do Preventon,have to check in run time
- The goal for deadlock avoidance is to the system must not enter an unsafe state.
- each process declares the maximum number of resources of each type that it may need
- deadlock-avoidance algorithm dynamically examines the resource-allocation state to ensure that there can never be a circular-wait condition
safe state
- safe state
- no deadlock
- unsafe state
- possibility of deadlock
- Avoidance Algorithms
- Single instance of a resource type
resource-allocation graph
- Multiple instances of a resource type
- Banker’s Algorithm
- Single instance of a resource type

Resource-Allocation Graph

- graph contains no cycles
- no deadlock
- graph contains a cycle
- only one instance per resource type, then deadlock
- several instances per resource type, possibility of deadlock
Banker’s Algorithm
- Max: request resource count to finish task
- Allocation: currently occupy resource count
- Need: Max-Allocation resource count
- Available: free count of resource type
Resource-Request Algorithm
example
- total available A (10 instances), B (5 instances), and C (7 instances)
- safe sequence:
- unsafe sequence:
| task | allocation | max | need | available | order |
|---|---|---|---|---|---|
| A,B,C | A,B,C | A,B,C | A,B,C | ||
| 0,1,0 | 7,5,3 | 7,4,3 | 7,4,5=( (7,4,3) + (0,0,2) ) | 3 | |
| 2,0,0 | 3,2,2 | 1,2,2 | 3,3,2=( (10,5,7) - (7,2,5) ) | 0 | |
| 3,0,2 | 9,0,2 | 6,0,2 | 7,5,5=( (7,4,5) + (0,1,0) ) | 4 | |
| 2,1,1 | 2,2,2 | 0,1,1 | 5,3,2=( (3,3,2) + (2,0,0) ) | 1 | |
| 0,0,2 | 4,3,3 | 4,3,1 | 7,4,3=( (5,3,2) + (2,1,1) ) | 2 |
Deadlock Detection
Single instance

Multiple instances:
- Total instances: A:7, B:2, C:6
- Available instances: A:0, B:0, C:0
| task | allocation | request/need |
|---|---|---|
| A,B,C | A,B,C | |
| 0,1,0 | 0,0,0 | |
| 2,0,0 | 2,0,2 | |
| 3,0,3 | 0,0,0 | |
| 2,1,1 | 1,0,0 | |
| 0,0,2 | 0,0,2 |
Deadlock Recovery
- Process termination
- Abort all deadlocked processes
- Abort one process at a time until the deadlock cycle is eliminated
- In which order should we choose to abort?
- Priority of the process
- How long process has computed
- Resources the process has used
- Resource preemption
- Selecting a victim
- minimize cost
- Rollback
- return to some safe state, restart process for that state
- Starvation
- same process may always be picked as victim, so we should include number of rollbacks in cost factor
- Selecting a victim
Chapter 9: Main Memory
- The only storage CPU can access directly
- Register access is done in one CPU clock (or less)
- Main memory can take many cycles, causing a stall
- Cache sits between main memory and CPU registers
Protection
- need to ensure that a process can only access those addresses in its address space
- we can provide this protection by using a pair of base and limit registers defining the logical address space of a process
- CPU must check every memory access generated in user mode to be sure it is between base and limit for that user

Logical vs. Physical Address
- Logical address/virtual address
- generated by the CPU
- Physical address
- address seen by the memory unit
- Logical and physical addresses are the same in compile- time and load-time address-binding schemes; they differ in execution-time address-binding scheme
Memory-Management Unit

How to refer memory in a program – Address Binding

- compile time
- load time
- execution time
How to load a program into memory – static/dynamic loading and linking
- Dynamic Loading
- load function instruct when need to use
- better memory space
- Static Linking
- duplicate same function instruct to memory in
compile time
- duplicate same function instruct to memory in
- Dynamic Linking
- runtime link function address
- DLL(Dynamic link library) in window
| Dynamic Loading | Static Linking | Dynamic Linking |
|---|---|---|
 |  |  |
Contiguous Memory Allocation
Variable-partition
Dynamic Storage Allocation Problem
- First-fit: Allocate the first hole that is big enough
- Best-fit: Allocate the smallest hole that is big enough; must search entire list, unless ordered by size
- Produces the smallest leftover hole
- Worst-fit: Allocate the largest hole; must also search entire list
- Produces the largest leftover hole
Fragmentation
- External fragmentation
- problem of variable-allocation
- free memory space enough to size but is not contiguous
- compaction
- Internal fragmentation
- problem of fix-partition-allocation
- memory not use by process

Non-Contiguous Memory Allocation
Paging
- Divide physical memory into fixed-sized blocks called
frame- size is power of 2, between 512 bytes and 16M bytes
- Divide logical memory into blocks of same size called
pages - To run a program of size N pages, need to find N free frames and load program
- benefit
- process of physical-address space can be non-contiguous
- avoid external fragmentation
Page table
- Page table only contain the page own by process
- process cant access memory that is not in
- Page table is kept in main memory
- Page-table base register (PTBR)
- points to the page table
- Page-table length register (PTLR)
- indicates size of the page table
- Page-table base register (PTBR)

Translation Look-aside Buffer (TLB)
- The two-memory access problem can be solved by the use of a special fast-lookup hardware cache called translation look-aside buffers (TLBs) (also called associative memory)
- In this scheme every data/instruction access requires
two memory accesses
address translation scheme

- Page number(p)
- each process can have page (32-bit computer one process can use 4GB memory)
- Page offset(d)
- combined with base address to define the physical memory address that is sent to the memory unit

- 給定一個 32-bits 的 logical address,36 bits 的 physical address 以及 4KB 的 page size,這代表?
- page table size = / = 個 entries
- Max program memory: = 4GB
- Total physical memory size = = 64GB
- Number of bits for page number = /= pages -> 20 bits
- Number of bits for frame number =/= frames -> 24 bits
- Number of bits for page offset = 4KB page size = bytes -> 12 bits
Shared Pages
- Shared code
- One copy of read-only (reentrant) code shared among processes

Chapter 10: Virtual Memory
- Code needs to be in memory to execute, but entire program rarely used
- Program no longer constrained by limits of physical memory
- Consider ability to execute partially-loaded program
virtual memory
- Only part of the program needs to be in memory for execution
- Logical address space can therefore be much larger than physical address space
- Allows address spaces to be shared by several processes
- Allows for more efficient process creation
- More programs running concurrently
- Less I/O needed to load or swap processes
- Virtual memory can be implemented via:
- Demand paging
- Demand segmentation

Demand Paging
- Page is needed
- Lazy swapper
- never swaps a page into memory unless page will be needed
- store in swap(disk)

valid-invalid bit
- During MMU address translation, if valid–invalid bit in page table entry is i => page fault

page fault
- page table that request are not in memory

free-frame list
- when page fault occurs, the OS must bring the desired page from secondary storage into main memory
- Most OS maintain a free-frame list – a pool of free frames for satisfying such requests
- zero-fill-on-demand
- the content of the frames zeroed-out before being allocated

Performance of Demand Paging
- Memory access time = 200 nanoseconds
- Average page-fault service time = 8000 nanoseconds
- p = page fault probability
- Effective Access Time = (1 – p) x 200 + p (8000)
Demand Paging Optimizations
- Swap space I/O faster than file system I/O even if on the same device
- Swap allocated in larger chunks, less management needed than file system
Copy-on-Write
- allows both parent and child processes to initially share the same pages in memory
- If either process modifies a shared page, only then is the page copied
- vfork() variation on fork()system call has parent suspend and child using copy-on-write address space of parent
- Designed to have child call exec()
- Very efficient
| origin | Process 1 Modifies Page C |
|---|---|
 |  |
Page Replacement
- if There is no Free Frame
- use a page replacement algorithm to select a victim frame
- Write victim frame to disk if dirty
- Bring the desired page into the (newly) free frame; update the page and frame tables
- Continue the process by restarting the instruction that caused the trap

FIFO Algorithm
- first in first out

Optimal Algorithm
- Replace page that will not be used for longest period of time
- stack algorithms

Least Recently Used (LRU) Algorithm
- Replace page that has not been used in the most amount of time
- stack algorithms

Second-chance Algorithm
- If page to be replaced has
- Reference bit = 0 -> replace it
- reference bit = 1 then:
- set reference bit 0, leave page in memory
- replace next page, subject to same rules
Counting Algorithms
- Least Frequently Used (LFU) Algorithm
- Most Frequently Used (LFU) Algorithm
page buffering algorithm
- Keep a pool of free frames, always
- possibly, keep list of modified pages
- Possibly, keep free frame contents intact and note what is in them
allocation of frames
- fixed allocation
- priority allocation
Non-Uniform Memory Access
allocating memory “close to” the CPU on which the thread is scheduled

thrashing

Page-Fault Frequency
- A process is busy swapping pages in and out
- If a process does not have “enough” pages, the page-fault rate is very high
- Page fault to get page
- Replace existing frame
- But quickly need replaced frame back
- If actual rate too low, process loses frame
- If actual rate too high, process gains frame

Buddy System
- Allocates memory from fixed-size segment consisting of physically-contiguous pages

Slab Allocator
- use by solaris and linux
- Slab can be in three possible states
- Full – all used
- Empty – all free
- Partial – mix of free and used
- Upon request, slab allocator
- Uses free struct in partial slab
- If none, takes one from empty slab
- If no empty slab, create new empty

Priority Allocation
- If process Pi generates a page fault,
- select for replacement one of its frames
- select for replacement a frame from a process with lower priority number
Chapter 11: Mass-Storage Systems
HDD(hard disk drives)
- Positioning time (random-access time)
- seek time
- calculated based on 1/3 of
tracks - 3ms to 12ms
- calculated based on 1/3 of
- rotational latency
- latency = 1 / (RPM / 60) =60/RPM
- average latency = latency
- seek time
- Transfer Rate
- Effective Transfer Rate (real): 1Gb/sec
- Access Latency
- Access Latency=average seek time + average latency
- Average I/O time
- Average I/O time = average access time + (amount to transfer / transfer rate) + controller overhead

Nonvolatile Memory Devices
- type
- solid-state disks (SSDs)
- usb
- drive writes per day (DWPD)
- A 1TB NAND drive with rating of 5DWPD is expected to have 5TB per day written within warrantee period without failing
Volatile Memory
- RAM drives
- RAM drives under user control
Disk Attachment
- STAT
- SAS
- USB
- FC
- NVMe
Disk Scheduling
- OS maintains queue of requests, per disk or device
- Minimize seek time
- Linux implements deadline scheduler
- Maintains separate read and write queues, gives read priority
- Because processes more likely to block on read than write
FCFS

SCAN algorithm
The disk arm starts at one end of the disk, and moves toward the other end, servicing requests until it gets to the other end of the disk, where the head movement is reversed and servicing continues

C-SCAN
SCAN but when it reaches the other end, however, it immediately returns to the beginning of the disk, without servicing any requests on the return trip

NVM Scheduling
- NVM best at random I/O, HDD at sequential
- write amplification
- one write, causing garbage collection and many read/writes
Error Detection and Correction
- CRC (checksum)
- ECC
Swap-Space Management
Used for moving entire processes (swapping), or pages (paging), from DRAM to secondary storage when DRAM not large enough for all processes
RAID Structure
- Mirroring
- Striped mirrors (RAID 1+0) or mirrored stripes (RAID 0+1) provides high performance and high reliability
- Block interleaved parity (RAID 4, 5, 6) uses much less redundancy

Chapter 13: File-System Interface
file attributes
Name – only information kept in human-readable form
- Identifier
- unique tag (number) identifies file within file system
- Type
- needed for systems that support different types
- Location
- pointer to file location on device
- Size
- current file size
- Protection
- controls who can do reading, writing, executing
- Time, date, and user identification
- data for protection, security, and usage monitoring
- Information about files are kept in the directory structure, which is maintained on the disk
- Many variations, including extended file attributes such as file checksum
file operations
- create
- write
- read
- seek
- delete
- truncate
file locking
- Shared lock
- Exclusive lock
- Mandatory
- access is denied depending on locks held and requested
- Advisory
- processes can find status of locks and decide what to do
File Structure
- simple record structure
- Lines
- Fixed length
- Variable length
- Complex Structures
- Formatted document
- Relocatable load file
types of File Systems
- tmpfs
- memory-based volatile FS for fast, temporary I/O
- objfs
- interface into kernel memory to get kernel symbols for debugging
- ctfs
- contract file system for managing daemons
- lofs
- loopback file system allows one FS to be accessed in place of another
- procfs
- kernel interface to process structures
- ufs, zfs
- general purpose file systems
Directory structure
- Naming problem
- convenient to users
- Two users can have the same name for different files
- The same file can have several different names
- Grouping problem
- logical grouping of files by properties,
- Efficient
- locating a file quickly
Two-Level Director

Tree-Structured Directories /Acyclic-Graph Directories

- guarantee no cycles?
- Garbage collection
- Every time a new link is added use a cycle detection algorithm to determine whether it is OK
File Sharing
- User IDs
- identify users, allowing permissions and protections to be per-user
- Group IDs
- allow users to be in groups, permitting group access rights


operating system
tags: software hardware system
Chapter 1: Computer System
Structure
One or more CPUs, device controllers connect through common bus providing access to shared memory
- Process Management
- Creating and deleting both user and system processes
- Suspending and resuming processes
- Providing mechanisms for process synchronization
- Providing mechanisms for process communication
- Providing mechanisms for deadlock handlin
- Memory Management
- Von Neumann architecture
- To execute a program, all (or part) of the instructions must be in memory
- All (or part) of the data that is needed by the program must be in memory
- Allocating and deallocating memory space as needed
- Keeping track of which parts of memory are currently being used and by whom
- Deciding which processes (or parts thereof) and data to move into and out of memory
- Von Neumann architecture
- file system management
- Abstracts physical properties to logical storage unit - file
- Access control on most systems to determine who can access what
- Mass-Storage Management
- mounting and unmounting
- fire-space management
- storage allocation
- disk scheduling
- partitioning
- protection
- caching management
- Faster storage (cache)
- mportant principle, performed at many levels in a computer (in hardware, operating system, software)
- I/O Subsystem
- buffering(storing data temporarily while it is being transferred)
- caching(storing part of data in faster storage for performance)
- spooling
operation
- I/O is from the device to local buffer of controller
- CPU moves data from/to main memory to/from local buffers
- Device controller informs CPU that it has finished its operation by causing an interrupt
interrupt
- software-generated interrupt :execption
- Modern OS is interrupt-driven
- Interrupt architecture must save the address of the interrupted instruction
Interrupt Handling
- The OS preserves the state of the CPU by storing the registers and the program counter
- type of interrupt
- polling
- vectored
I/O
handling I/O
- Synchronous: After I/O starts, control returns to user program only upon I/O completion
- wait instruction idles the cpu until the next interrupt
- wait loop
- Asynchronous: After I/O starts, control returns to user program without waiting for I/O completion
- system call:request to the OS to allow user to wait for I/O completion
storage structure
- main memory
- cpu can access directly
- Dynamic Random-access Memory (DRAM)
- Typically volatile
- HDD
- Non-volatile memory (NVM)
Direct Memory Access(DMA)
- Used for high-speed I/O devices able to transmit information at close to memory speeds
- Device controller transfers blocks of data from buffer storage directly to main memory without CPU intervention
- Only one interrupt is generated per block, rather than one interrupt per byte
Symmetric Multiprocessing Architecture
| Dual-Core Design | Non-Uniform Memory Access System |
|---|---|
| |
Virtualization
have different kernel
cloud computing
- Software as a Service (SaaS)
- one or more applications available via the Internet (i.e., word processor)
- Platform as a Service (PaaS)
- software stack ready for application use via the Internet (i.e., a database server)
- Infrastructure as a Service (IaaS)
- servers or storage available over Internet (i.e., storage available for backup use)
Kernel Data Structures
Chapter 2: Operating-System Service
System Calls
- Programming interface to the services provided by the OS
- Typically written in a high-level language (C or C++)
- Mostly accessed by programs via a high-level Application Programming Interface (API) rather than direct system call
- System Call Parameter Passing
- pushed, onto the stack by the program and popped off the stack by the OS
- pushed, onto the stack by the program and popped off the stack by the OS
Types of System Calls
- Process control
- create process, terminate process
- end, abort
- load, execute
- get process attributes, set process attributes
- wait for time
- wait event, signal event
- allocate and free memory
- Dump memory if error
- Debugger for determining bugs, single step execution
- Locks for managing access to shared data between
- File management
- create file, delete file
- open, close file
- read, write, reposition
- get and set file attributes
- Device management
- request device, release device
- read, write, reposition
- get device attributes, set device attributes
- logically attach or detach devices processes
- Information maintenance
- get time or date, set time or date
- get system data, set system data
- get and set process, file, or device attributes
- Communications
- create, delete communication connection
- send, receive messages if message passing model to host name or process name
- From client to server
- Shared-memory model create and gain access to memory regions
- transfer status information
- attach and detach remote devices
program stack
Linker and Loader
- Source code compiled into object files designed to be loaded into any physical memory location – relocatable object file
- Linker combines these into single binary executable file
- Also brings in libraries
- Modern general purpose systems don’t link libraries into executables
- Rather, dynamically linked libraries (in Windows, DLLs) are loaded as needed, shared by all that use the same version of that same library (loaded once
Operating System Structure
- Simple structure
- Monolithic Structure More
- Microkernel
- Layered
- Hybrid
Traditional UNIX System Structure
- UNIX:
- limited by hardware functionality, the original UNIX OS had limited structuring
- Consists of everything below the system-call interface and above the physical hardware
- Provides the file system, CPU scheduling, memory management, and other OS functions; a large number of functions for one level
Linux System Structure
Monolithic plus modular design
Microkernels
- Moves as much from the kernel into user space
- Mach is an example of microkernel
- Mac OS X kernel (Darwin) partly based on Mach
- Benefits:
- Easier to extend a microkernel
- Easier to port the OS to new architectures
- More reliable (less code is running in kernel mode)
- More secure
- Detriments:
- Performance overhead of user space to kernel space communication
Layered Approach
- The OS is divided into a number of layers (levels), each built on top of lower layers
- The bottom layer (layer 0), is the hardware
- the highest (layer N) is the user interface
- With modularity, layers are selected such that each uses functions (operations) and services of only lower- level layers
hybrid systems
- Apple Mac OS X hybrid, layered, Aqua UI plus Cocoa programming environment
| macOS iOS | darwin | android |
|---|---|---|
| | |
System Boot
- When power initialized on system, execution starts at a fixed memory location
- Small piece of code
- bootstrap loader, BIOS, stored in ROM or EEPROM locates the kernel, loads it into memory, and starts it
- Modern systems replace BIOS with Unified Extensible Firmware Interface (UEFI)
- Common bootstrap loader, GRUB
tracing
- strace – trace system calls invoked by a process
- gdb – source-level debugger
- perf – collection of Linux performance tools
- tcpdump – collects network packets
Chapter 3: Processes
- The program code, also called text section
- Current activity including program counter, processor registers
- Stack containing temporary data
- Function parameters, return addresses, local variables
- Data section containing global variables
- Heap containing memory dynamically allocated during run time
process state
- new
- running
- waiting
- ready:the process is waiting to be assigned to a processor
- terminated
Process Scheduling
Process Control Block (PCB) or task control block)
scheduling
- Goal – Maximize CPU use, quickly switch
- processes onto CPU core
- Maintains scheduling queues of processes
- ready queue
- wait queue
context switch
- context-switch time is pure overhead; the system does no useful work while switching
- The more complex the OS and the PCB the longer the context switch
- Time dependent on hardware support
- Some hardware provides multiple sets of registers per CPU multiple contexts loaded at once
Operations on Processes
Inter Process Communication(IPC)
- shared memory
- message passing
IPC in Shared-Memory Systems
- An area of memory shared among the processes that wish to communicate
- The communication is under the control of the user processes not the OS
IPC in Message-Passing Systems
- Blocking is considered synchronous
- Non-blocking is considered asynchronous
Ordinary pipes
- unidirectional(single direction)
- cannot be accessed from outside the process that created it.
- Typically, a parent process creates a pipe and uses it to communicate with a child process that it created
named pipes
- Communication is bidirectional
- No parent-child relationship is necessary between the communicating processes
Client-Server Systems
| sockets | Remote Procedure Calls (RPC) |
|---|---|
| |
Chapter 4: Threads & Concurrency
Concurrency vs. Parallelism
Multicore Programming
- Data parallelism
- different data, same operation on each data
- Task parallelism
- different operation, same data
Amdahl’s Law
Multithreading Models
- Many-to-One
- One thread blocking causes all to block
- example
- solaris green threads
- GUN portable threads
- One-to-One
- More concurrency than many-to-one
- example
- windows
- linux
- Many-to-Many
- Windows with the ThreadFiber package
- two-level model
- mix Many-to-Many and One-To-One
| Many-to-One | ono-to-one | Many-to-Many | two-level model |
|---|---|---|---|
| | | |
Implicit threading
- Thread Pools
- Create a number of threads in a pool where they await work
- Fork-Join Parallelism
- OpenMP
- Grand Central Dispatch
- dispatch queues
- macOS,iOS
Chapter 5: CPU Scheduling
CPU scheduler
- CPU utilization
- keep the CPU as busy as possible
- Throughput
- of processes that complete their execution per time unit
- Turnaround time
- amount of time to execute a particular process
- turnaround time = completion time – arrival time
- Waiting time
- amount of time a process has been waiting in the ready queue
- waiting time = turnaround time – burst time
- Response time
- amount of time it takes from when a request was submitted until the first response is produce
- response time = start time – arrival time
CPU scheduling decisions may take place when a process:
- Switches from running to waiting state
- Switches from running to ready state
- Switches from waiting to ready
- Terminates
Preemptive
- preemptive
- can result in race conditions
- linux,windows,MacOS
- nonpreemptive
- only under circumstances 1 and 4
Dispatcher
- witching context
- Switching to user mode
- Jumping to the proper location in the user program to restart that program
Dispatch latency =time it take to stop one process and start another running
Scheduling Algorithm
- Max CPU utilization
- Max throughput
- Min turnaround time
- Min waiting time
- Min response time
Determining Length of Next CPU Burst
- exponential averaging
First- Come, First-Served(FCFS) Scheduling
- Convoy effect short process behind long process
- Consider one CPU-bound and many I/O-bound processes
Shortest-Job-First(SJF) Scheduling
- minimum average waiting time for a given set of processes
shortest-remaining-time-first(Preemptive SJF)
| process | arrival time | burst time |
|---|---|---|
| 0 | 8 | |
| 1 | 4 | |
| 2 | 9 | |
| 3 | 5 |
Round Robin (RR)
- Each process gets a small unit of CPU time (time quantum q), usually 10-100 milliseconds
- After this time has elapsed, the process is preempted and added to the end of the ready queue
- Typically, higher average turnaround than
SJF, but better response
| process | burst time |
|---|---|
| 8 | |
| 4 | |
| 9 |
Priority Scheduling
- The CPU is allocated to the process with the highest priority
SJFis priority scheduling where priority is the inverse of predicted next CPU burst time
| process | burst time | priority |
|---|---|---|
| 10 | 3 | |
| 1 | 1 | |
| 2 | 4 | |
| 1 | 5 | |
| 5 | 2 |
Priority Scheduling + Round-Robin
- Run the process with the highest priority
- Processes with the same priority run round-robin
| process | burst time | priority |
|---|---|---|
| 7 | 1 | |
| 5 | 2 | |
| 8 | 2 | |
| 4 | 3 | |
| 3 | 3 |
Multilevel Queue
Multiple-Processor Scheduling
- Multicore CPUs
- Multithreaded cores
- NUMA(non-uniform memory access) systems
- Heterogeneous multiprocessing
SMP
- Symmetric multiprocessing (SMP) is where each processor is self-scheduling
- (a) All threads may be in a common ready queue
- (b) Each processor may have its own private queue of threads
- keep all CPUs loaded for efficiency
- Load balancing
- attempts to keep workload evenly distributed
- push migration
- pushes task from overloaded CPU to other CPUs
- pull migration
- idle processors pulls waiting task from busy processor
- Load balancing
- processor affinity
- Soft affinity
- the OS attempts to keep a thread running on the same processor, but no guarantees
- Hard affinity
- allows a process to specify a set of processors it may run on
- Soft affinity
hyperthreading
real-time scheduling
- Real-Time system
- soft real-time system
- but no guarantee as to when tasks will be scheduled
- hard real-time system
- task must be serviced by its deadline
- soft real-time system
- latency
- Interrupt latency
- time of stop process to another process
- Dispatch latency
- take current process off CPU and switch to another CPU
- Interrupt latency
Earliest Deadline First Scheduling (EDF)
- Priorities are assigned according to deadlines:
- the earlier the deadline, the higher the priority
- the later the deadline, the lower the priority
Operating System Examples
linux scheduling
- Completely Fair Scheduler (CFS)
- CFS scheduler maintains per task virtual run time in variable vruntime
- To decide next task to run, scheduler picks task with lowest virtual run time
- Linux supports load balancing, but is also NUMA-aware
solaris scheduling
- priority-based scheduling
- Six classes available
- Time sharing (default) (TS)
- Interactive (IA)
- Real time (RT)
- System (SYS)
- Fair Share (FSS)
- Fixed priority (FP)
Chapter 6: Synchronization Tools
Race condition
critical sectionsegment of code- Process may be changing common variables, updating table, writing file, etc
- When one process in critical section, no other may be in its critical section
Critical-Section Problem
- Mutual Exclusion
- If process is executing in its critical section, then no other processes can be executing in their critical sections
- Progress
- if not process in critical section and have process want to enter critical section then have to let the process
- Bounded Waiting
- the time process wait to enter critical section have to limit(cant wait forever)
software solution
- cant avoid shared variable be override value by another process
- Entry section: disable interrupts
- Exit section: enable interrupts
part of Solution
-
Assume that the
loadandstoremachine-language instructions areatomic- Which cannot be interrupted
-
turnindicates whose turn it is to enter the critical section -
two process have enter critical section in turn
Peterson’s Solution
- Assume that the
loadandstoremachine-language instructions areatomic- Which cannot be interrupted
turnindicates whose turn it is to enter the critical sectionflagarray is used to indicate if a process is ready to enter the critical section- solve
critical section problem- Mutual exclusion
- progress
- bounded-waiting
Memory Barrier
- Memory models may be either:
- Strongly ordered – where a memory modification of one processor is immediately visible to all other processors
- Weakly ordered – where a memory modification of one processor may not be immediately visible to all other processors
Mutex Locks
- First acquire() a lock
- Then release() the lock
busy waiting- the process will be block and continuous check is lock
spinlockwhen is lock free will automatic let the waiting process know
semaphore
- wait()
- signal()
- Counting semaphore
- integer value can range over an unrestricted domain
- Binary semaphore
- integer value can range only between 0 and 1
- Same as a mutex lock
- Must guarantee that no two processes can execute the
wait()andsignal()on the same semaphore at the same time
Semaphore Implementation with no Busy waiting
- block()
- place the process invoking the operation on the appropriate waiting queue
- wakeup()
- remove one of processes in the waiting queue and place it in the ready queue
Synchronization Hardware
- Hardware instruction
- Atomic Swap()
- Test and Set()
- Atomic variables
Hardware instruction
Atomic variables
- atomic variable that provides atomic (uninterruptible) updates on basic data types such as integers and booleans
deadlock
- deadlock
- two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes
- Starvation
- indefinite blocking
- A process may never be removed from the semaphore queue in which it is suspended
- Priority Inversion
- Scheduling problem when lower-priority process holds a lock needed by higher-priority process
- Solved via priority-inheritance protocol
Chapter 7: Synchronization Examples
Problems of Synchronization
Most of the synchronization problems do not exist in functional languages
- Bounded-Buffer Problem (Producer-consumer problem)
- Readers and Writers Problem
- Dining-Philosophers Problem
OS
- windows
- spinlocks
- dispatcher object
- linux
- Atomic integers
- Mutex locks
- Spinlocks, Semaphores
- Reader-writer versions of both
- POSIX
- mutex locks
- semaphores
- named
- can be used by unrelated processes
- unnamed
- can be used only by threads in the same process
- named
- condition variable
Chapter 8: Deadlocks
Deadlock Characterization
- Mutual exclusion
- only one process at a time can use a resource
- Hold and wait
- a process holding at least one resource is waiting to acquire additional resources held by other processes
- No preemption
- a resource can be released only voluntarily by the process holding it, after that process has completed its task
- Circular wait
- there exists a set {P0, P1, …, Pn} of waiting processes such that:
Deadlocks Prevention
- mutual exclusion
- not required for sharable resources (e.g., read-only files); must hold for non-sharable resource
- hold and wait
- must guarantee that whenever a process requests a resource, it does not hold any other resources
- No Preemption
- If a process that is holding some resources requests another resource that cannot be immediately allocated to it, then all resources currently being held are released
- Circular Wai
- check is have circular wait or not
Deadlock Avoidance
- Cant do Preventon,have to check in run time
- The goal for deadlock avoidance is to the system must not enter an unsafe state.
- each process declares the maximum number of resources of each type that it may need
- deadlock-avoidance algorithm dynamically examines the resource-allocation state to ensure that there can never be a circular-wait condition
safe state
- safe state
- no deadlock
- unsafe state
- possibility of deadlock
- Avoidance Algorithms
- Single instance of a resource type
resource-allocation graph
- Multiple instances of a resource type
- Banker’s Algorithm
- Single instance of a resource type
Resource-Allocation Graph
- graph contains no cycles
- no deadlock
- graph contains a cycle
- only one instance per resource type, then deadlock
- several instances per resource type, possibility of deadlock
Banker’s Algorithm
- Max: request resource count to finish task
- Allocation: currently occupy resource count
- Need: Max-Allocation resource count
- Available: free count of resource type
Resource-Request Algorithm
example
- total available A (10 instances), B (5 instances), and C (7 instances)
- safe sequence:
- unsafe sequence:
| task | allocation | max | need | available | order |
|---|---|---|---|---|---|
| A,B,C | A,B,C | A,B,C | A,B,C | ||
| 0,1,0 | 7,5,3 | 7,4,3 | 7,4,5=( (7,4,3) + (0,0,2) ) | 3 | |
| 2,0,0 | 3,2,2 | 1,2,2 | 3,3,2=( (10,5,7) - (7,2,5) ) | 0 | |
| 3,0,2 | 9,0,2 | 6,0,2 | 7,5,5=( (7,4,5) + (0,1,0) ) | 4 | |
| 2,1,1 | 2,2,2 | 0,1,1 | 5,3,2=( (3,3,2) + (2,0,0) ) | 1 | |
| 0,0,2 | 4,3,3 | 4,3,1 | 7,4,3=( (5,3,2) + (2,1,1) ) | 2 |
Deadlock Detection
Single instance
Multiple instances:
- Total instances: A:7, B:2, C:6
- Available instances: A:0, B:0, C:0
| task | allocation | request/need |
|---|---|---|
| A,B,C | A,B,C | |
| 0,1,0 | 0,0,0 | |
| 2,0,0 | 2,0,2 | |
| 3,0,3 | 0,0,0 | |
| 2,1,1 | 1,0,0 | |
| 0,0,2 | 0,0,2 |
Deadlock Recovery
- Process termination
- Abort all deadlocked processes
- Abort one process at a time until the deadlock cycle is eliminated
- In which order should we choose to abort?
- Priority of the process
- How long process has computed
- Resources the process has used
- Resource preemption
- Selecting a victim
- minimize cost
- Rollback
- return to some safe state, restart process for that state
- Starvation
- same process may always be picked as victim, so we should include number of rollbacks in cost factor
- Selecting a victim
Chapter 9: Main Memory
- The only storage CPU can access directly
- Register access is done in one CPU clock (or less)
- Main memory can take many cycles, causing a stall
- Cache sits between main memory and CPU registers
Protection
- need to ensure that a process can only access those addresses in its address space
- we can provide this protection by using a pair of base and limit registers defining the logical address space of a process
- CPU must check every memory access generated in user mode to be sure it is between base and limit for that user
Logical vs. Physical Address
- Logical address/virtual address
- generated by the CPU
- Physical address
- address seen by the memory unit
- Logical and physical addresses are the same in compile- time and load-time address-binding schemes; they differ in execution-time address-binding scheme
Memory-Management Unit
How to refer memory in a program – Address Binding
- compile time
- load time
- execution time
How to load a program into memory – static/dynamic loading and linking
- Dynamic Loading
- load function instruct when need to use
- better memory space
- Static Linking
- duplicate same function instruct to memory in
compile time
- duplicate same function instruct to memory in
- Dynamic Linking
- runtime link function address
- DLL(Dynamic link library) in window
| Dynamic Loading | Static Linking | Dynamic Linking |
|---|---|---|
| | |
Contiguous Memory Allocation
Variable-partition
Dynamic Storage Allocation Problem
- First-fit: Allocate the first hole that is big enough
- Best-fit: Allocate the smallest hole that is big enough; must search entire list, unless ordered by size
- Produces the smallest leftover hole
- Worst-fit: Allocate the largest hole; must also search entire list
- Produces the largest leftover hole
Fragmentation
- External fragmentation
- problem of variable-allocation
- free memory space enough to size but is not contiguous
- compaction
- Internal fragmentation
- problem of fix-partition-allocation
- memory not use by process
Non-Contiguous Memory Allocation
Paging
- Divide physical memory into fixed-sized blocks called
frame- size is power of 2, between 512 bytes and 16M bytes
- Divide logical memory into blocks of same size called
pages - To run a program of size N pages, need to find N free frames and load program
- benefit
- process of physical-address space can be non-contiguous
- avoid external fragmentation
Page table
- Page table only contain the page own by process
- process cant access memory that is not in
- Page table is kept in main memory
- Page-table base register (PTBR)
- points to the page table
- Page-table length register (PTLR)
- indicates size of the page table
- Page-table base register (PTBR)
Translation Look-aside Buffer (TLB)
- The two-memory access problem can be solved by the use of a special fast-lookup hardware cache called translation look-aside buffers (TLBs) (also called associative memory)
- In this scheme every data/instruction access requires
two memory accesses
address translation scheme
- Page number(p)
- each process can have page (32-bit computer one process can use 4GB memory)
- Page offset(d)
- combined with base address to define the physical memory address that is sent to the memory unit
- 給定一個 32-bits 的 logical address,36 bits 的 physical address 以及 4KB 的 page size,這代表?
- page table size = / = 個 entries
- Max program memory: = 4GB
- Total physical memory size = = 64GB
- Number of bits for page number = /= pages -> 20 bits
- Number of bits for frame number =/= frames -> 24 bits
- Number of bits for page offset = 4KB page size = bytes -> 12 bits
Shared Pages
- Shared code
- One copy of read-only (reentrant) code shared among processes
Chapter 10: Virtual Memory
- Code needs to be in memory to execute, but entire program rarely used
- Program no longer constrained by limits of physical memory
- Consider ability to execute partially-loaded program
virtual memory
- Only part of the program needs to be in memory for execution
- Logical address space can therefore be much larger than physical address space
- Allows address spaces to be shared by several processes
- Allows for more efficient process creation
- More programs running concurrently
- Less I/O needed to load or swap processes
- Virtual memory can be implemented via:
- Demand paging
- Demand segmentation
Demand Paging
- Page is needed
- Lazy swapper
- never swaps a page into memory unless page will be needed
- store in swap(disk)
valid-invalid bit
- During MMU address translation, if valid–invalid bit in page table entry is i => page fault
page fault
- page table that request are not in memory
free-frame list
- when page fault occurs, the OS must bring the desired page from secondary storage into main memory
- Most OS maintain a free-frame list – a pool of free frames for satisfying such requests
- zero-fill-on-demand
- the content of the frames zeroed-out before being allocated
Performance of Demand Paging
- Memory access time = 200 nanoseconds
- Average page-fault service time = 8000 nanoseconds
- p = page fault probability
- Effective Access Time = (1 – p) x 200 + p (8000)
Demand Paging Optimizations
- Swap space I/O faster than file system I/O even if on the same device
- Swap allocated in larger chunks, less management needed than file system
Copy-on-Write
- allows both parent and child processes to initially share the same pages in memory
- If either process modifies a shared page, only then is the page copied
- vfork() variation on fork()system call has parent suspend and child using copy-on-write address space of parent
- Designed to have child call exec()
- Very efficient
| origin | Process 1 Modifies Page C |
|---|---|
| |
Page Replacement
- if There is no Free Frame
- use a page replacement algorithm to select a victim frame
- Write victim frame to disk if dirty
- Bring the desired page into the (newly) free frame; update the page and frame tables
- Continue the process by restarting the instruction that caused the trap
FIFO Algorithm
- first in first out
Optimal Algorithm
- Replace page that will not be used for longest period of time
- stack algorithms
Least Recently Used (LRU) Algorithm
- Replace page that has not been used in the most amount of time
- stack algorithms
Second-chance Algorithm
- If page to be replaced has
- Reference bit = 0 -> replace it
- reference bit = 1 then:
- set reference bit 0, leave page in memory
- replace next page, subject to same rules
Counting Algorithms
- Least Frequently Used (LFU) Algorithm
- Most Frequently Used (LFU) Algorithm
page buffering algorithm
- Keep a pool of free frames, always
- possibly, keep list of modified pages
- Possibly, keep free frame contents intact and note what is in them
allocation of frames
- fixed allocation
- priority allocation
Non-Uniform Memory Access
allocating memory “close to” the CPU on which the thread is scheduled
thrashing
Page-Fault Frequency
- A process is busy swapping pages in and out
- If a process does not have “enough” pages, the page-fault rate is very high
- Page fault to get page
- Replace existing frame
- But quickly need replaced frame back
- If actual rate too low, process loses frame
- If actual rate too high, process gains frame
Buddy System
- Allocates memory from fixed-size segment consisting of physically-contiguous pages
Slab Allocator
- use by solaris and linux
- Slab can be in three possible states
- Full – all used
- Empty – all free
- Partial – mix of free and used
- Upon request, slab allocator
- Uses free struct in partial slab
- If none, takes one from empty slab
- If no empty slab, create new empty
Priority Allocation
- If process Pi generates a page fault,
- select for replacement one of its frames
- select for replacement a frame from a process with lower priority number
Chapter 11: Mass-Storage Systems
HDD(hard disk drives)
- Positioning time (random-access time)
- seek time
- calculated based on 1/3 of
tracks - 3ms to 12ms
- calculated based on 1/3 of
- rotational latency
- latency = 1 / (RPM / 60) =60/RPM
- average latency = latency
- seek time
- Transfer Rate
- Effective Transfer Rate (real): 1Gb/sec
- Access Latency
- Access Latency=average seek time + average latency
- Average I/O time
- Average I/O time = average access time + (amount to transfer / transfer rate) + controller overhead
Nonvolatile Memory Devices
- type
- solid-state disks (SSDs)
- usb
- drive writes per day (DWPD)
- A 1TB NAND drive with rating of 5DWPD is expected to have 5TB per day written within warrantee period without failing
Volatile Memory
- RAM drives
- RAM drives under user control
Disk Attachment
- STAT
- SAS
- USB
- FC
- NVMe
Disk Scheduling
- OS maintains queue of requests, per disk or device
- Minimize seek time
- Linux implements deadline scheduler
- Maintains separate read and write queues, gives read priority
- Because processes more likely to block on read than write
FCFS
SCAN algorithm
The disk arm starts at one end of the disk, and moves toward the other end, servicing requests until it gets to the other end of the disk, where the head movement is reversed and servicing continues
C-SCAN
SCAN but when it reaches the other end, however, it immediately returns to the beginning of the disk, without servicing any requests on the return trip
NVM Scheduling
- NVM best at random I/O, HDD at sequential
- write amplification
- one write, causing garbage collection and many read/writes
Error Detection and Correction
- CRC (checksum)
- ECC
Swap-Space Management
Used for moving entire processes (swapping), or pages (paging), from DRAM to secondary storage when DRAM not large enough for all processes
RAID Structure
- Mirroring
- Striped mirrors (RAID 1+0) or mirrored stripes (RAID 0+1) provides high performance and high reliability
- Block interleaved parity (RAID 4, 5, 6) uses much less redundancy
Chapter 13: File-System Interface
file attributes
Name – only information kept in human-readable form
- Identifier
- unique tag (number) identifies file within file system
- Type
- needed for systems that support different types
- Location
- pointer to file location on device
- Size
- current file size
- Protection
- controls who can do reading, writing, executing
- Time, date, and user identification
- data for protection, security, and usage monitoring
- Information about files are kept in the directory structure, which is maintained on the disk
- Many variations, including extended file attributes such as file checksum
file operations
- create
- write
- read
- seek
- delete
- truncate
file locking
- Shared lock
- Exclusive lock
- Mandatory
- access is denied depending on locks held and requested
- Advisory
- processes can find status of locks and decide what to do
File Structure
- simple record structure
- Lines
- Fixed length
- Variable length
- Complex Structures
- Formatted document
- Relocatable load file
types of File Systems
- tmpfs
- memory-based volatile FS for fast, temporary I/O
- objfs
- interface into kernel memory to get kernel symbols for debugging
- ctfs
- contract file system for managing daemons
- lofs
- loopback file system allows one FS to be accessed in place of another
- procfs
- kernel interface to process structures
- ufs, zfs
- general purpose file systems
Directory structure
- Naming problem
- convenient to users
- Two users can have the same name for different files
- The same file can have several different names
- Grouping problem
- logical grouping of files by properties,
- Efficient
- locating a file quickly
Two-Level Director
Tree-Structured Directories /Acyclic-Graph Directories
- guarantee no cycles?
- Garbage collection
- Every time a new link is added use a cycle detection algorithm to determine whether it is OK
File Sharing
- User IDs
- identify users, allowing permissions and protections to be per-user
- Group IDs
- allow users to be in groups, permitting group access rights
hw1
1
- a.
- The CPU can initiate a DMA (Direct Memory Access) operation by writing values into special registers that can be independently accessed by the device.
- b.
- When the device is finished with its operation, it interrupts the CPU to indicate the completion of the operation.
- c.
- Yes, If the DMA and CPU access the memory at same time may generate coherency issue since it have different value with caches.
2.15
- message-passing model
- pros: simple
- cons: only apply for smaller amounts of data
- shared-memory model
- pros: need to avoid race condition
- cons: apply for large amoung data
2.19
- Pros:
- Easier to extend a microkernel
- Easier to port the OS to new architectures
- More reliable (less code is running in kernel mode)
- More secure
- Cons:
- Performance overhead of user space to kernel space communication
- How do user programs and system services interact in a microkernel architecture?
- Communication takes place between user modules using message passing
3.12
the system save the state of the old process and load the saved state for the new process via a context switch
3.18
-
ordinary pipes are better when
- communication between two specific processes on the same machine
-
named pipes are better when
- we want to communicate over a network
- relation is bidirectional and there is no parent child relationship between processes.
programming exercises
2.24
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
void Copy(char *out, char *in)
{
int c;
FILE *inPtr = fopen(in, "r");
FILE *outPtr = fopen(out, "w");
if (!inPtr)
{
perror("Source file can't be opened: ");
exit(1);
}
if (!outPtr)
{
perror("Destination file can't be opened: ");
exit(1);
}
// Copy file one char at a time and terminate loop when c reaches end of file (EOF)
while ((c = fgetc(inPtr)) != EOF)
{
fputc(c, outPtr);
}
// if all the above lines get executed, then the program has run successfully
printf("Success!\n");
// close files
fclose(inPtr);
fclose(outPtr);
}
int main(int argc, char *argv[])
{
if (argc < 3)
{
fprintf(stderr, "Usage: %s <source> <destination>\n", argv[0]);
return EXIT_FAILURE;
}
printf("copy %s to %s\n", argv[1], argv[2]);
Copy(argv[2], argv[1]);
return EXIT_SUCCESS;
}
3.19 part 1
share memory
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <string.h>
#include <sys/mman.h>
#include <fcntl.h>
#define SHM_SIZE sizeof(struct timeval)
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <command>\n", argv[0]);
return EXIT_FAILURE;
}
struct timeval *start_time_ptr;
int shm_fd;
pid_t pid;
void *shm_ptr;
// Create shared memory
shm_fd = shm_open("/time_shm", O_CREAT | O_RDWR, 0666);
if (shm_fd == -1) {
perror("shm_open");
return EXIT_FAILURE;
}
// Set the size of the shared memory segment
ftruncate(shm_fd, SHM_SIZE);
// Map the shared memory segment to the address space of the process
shm_ptr = mmap(0, SHM_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shm_fd, 0);
if (shm_ptr == MAP_FAILED) {
perror("mmap");
return EXIT_FAILURE;
}
start_time_ptr = (struct timeval *)shm_ptr;
pid = fork();
if (pid == -1) {
perror("fork");
return EXIT_FAILURE;
} else if (pid == 0) { // Child process
gettimeofday(start_time_ptr, NULL);
execvp(argv[1], &argv[1]);
// execvp only returns if an error occurs
perror("execvp");
exit(EXIT_FAILURE);
} else { // Parent process
wait(NULL);
struct timeval end_time;
gettimeofday(&end_time, NULL);
struct timeval start_time = *start_time_ptr;
// Calculate elapsed time
long elapsed_sec = end_time.tv_sec - start_time.tv_sec;
long elapsed_usec = end_time.tv_usec - start_time.tv_usec;
if (elapsed_usec < 0) {
elapsed_sec--;
elapsed_usec += 1000000;
}
printf("Elapsed time: %ld.%06ld seconds\n", elapsed_sec, elapsed_usec);
}
// Cleanup
munmap(shm_ptr, SHM_SIZE);
close(shm_fd);
shm_unlink("/time_shm");
return EXIT_SUCCESS;
}
3.19 part 2
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#define READ_END 0
#define WRITE_END 1
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <command>\n", argv[0]);
return EXIT_FAILURE;
}
int pipe_fd[2];
pid_t pid;
struct timeval start_time, end_time;
if (pipe(pipe_fd) == -1) {
perror("pipe");
return EXIT_FAILURE;
}
pid = fork();
if (pid == -1) {
perror("fork");
return EXIT_FAILURE;
} else if (pid == 0) { // Child process
close(pipe_fd[READ_END]); // Close the read end of the pipe
gettimeofday(&start_time, NULL);
write(pipe_fd[WRITE_END], &start_time, sizeof(struct timeval));
close(pipe_fd[WRITE_END]);
execvp(argv[1], &argv[1]);
// execvp only returns if an error occurs
perror("execvp");
exit(EXIT_FAILURE);
} else { // Parent process
close(pipe_fd[WRITE_END]); // Close the write end of the pipe
wait(NULL);
read(pipe_fd[READ_END], &start_time, sizeof(struct timeval));
close(pipe_fd[READ_END]);
gettimeofday(&end_time, NULL);
// Calculate elapsed time
long elapsed_sec = end_time.tv_sec - start_time.tv_sec;
long elapsed_usec = end_time.tv_usec - start_time.tv_usec;
if (elapsed_usec < 0) {
elapsed_sec--;
elapsed_usec += 1000000;
}
printf("Elapsed time: %ld.%06ld seconds\n", elapsed_sec, elapsed_usec);
}
return EXIT_SUCCESS;
}
hw2
4.8
I/O heavy task because mulithreading not speedup I/O speed
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREADS 4
#define ITERATIONS_PER_THREAD 10
void *io_bound_task(void *thread_id) {
long tid;
tid = (long)thread_id;
FILE *file;
char filename[20];
sprintf(filename, "file_%ld.txt", tid);
for (int i = 0; i < ITERATIONS_PER_THREAD; i++) {
file = fopen(filename, "a");
if (file != NULL) {
fprintf(file, "Thread %ld writing to file %d\n", tid, i);
fclose(file);
}
}
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int rc;
long t;
for (t = 0; t < NUM_THREADS; t++) {
rc = pthread_create(&threads[t], NULL, io_bound_task, (void *)t);
if (rc) {
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
pthread_exit(NULL);
}
4.10
- B. Heap memory
- C. Global variables
4.16
- How many threads will you create to perform the input and output? Explain.
- 1 threads
- input and output require single file operation which is cant be parallel
- How many threads will you create for the CPU-intensive portion of the application? Explain
- 4 thread
- since task can be parallel to reduce time
5.14
- Each processing core has its own run queue
- Advantages
- better cache utilization
- Disadvantages
- increased complexity
- Advantages
- single run queue
- Advantages
- easy balanced workload
- Disadvantages
- thread cache coherence
- Advantages
5.18
| process | priority | burst time | arrival |
|---|---|---|---|
| 8 | 15 | 0 | |
| 3 | 20 | 0 | |
| 4 | 20 | 20 | |
| 4 | 20 | 25 | |
| 5 | 5 | 45 | |
| 10 | 15 | 55 |
---
displayMode: compact
---
gantt
title task scheduling order
dateFormat X
axisFormat %s
tickInterval 5second
section P1 priority 8
P1 : 0, 15
section P2 priority 3
P2 : 15, 20
P2 : 80, 95
section P3 priority 4
P3 : 20, 30
P3 : 40, 45
P3 : 70, 75
section P4 priority 4
P4 : 30, 40
P4 : 50, 55
P4 : 75, 80
section P5 priority 5
P5 : 45, 50
section P6 priority 10
P6 : 55, 70
| turnaround time | waiting time | |
|---|---|---|
| P1 | 15-0=15 | 0 |
| P2 | 95-0=95 | 95-20=75 |
| P3 | 75-20=55 | 55-20=35 |
| P4 | 80-25=55 | 55-20=35 |
| P5 | 50-45=5 | 0 |
| P6 | 70-55=15 | 0 |
5.22
The time quantum is 1 millisecond
The time quantum is 10 millisecond
5.25
- FCFS
- run task by arrival time
- doesn’t discriminate in favor of short processes
- RR
- keep each process be run by CPU equality
- doesn’t discriminate in favor of short processes
- Multilevel Feedback queues
- can prioritize short processes by setting
6.7
push(item) {
if (top < SIZE) {
stack[top] = item;
top++;
}
else
ERROR
}
pop() {
if (lis_empty()) {
top--;
return stack[top];
}
else
ERROR
}
is_empty() {
if (top == 0)
return true;
else
return false;
}
- (a)
top
- (b)
- add mutex so only one process can access
topat time
- add mutex so only one process can access
6.15
- Potential Deadlocks: because process hold lock cant be interrupts
- Loss of responsiveness: be interrupts by I/O operation
6.18
- block()
- place the process invoking the operation on the appropriate waiting queue
- wakeup()
- remove one of processes in the waiting queue and place it in the ready queue
programming problems
4.27
#include <pthread.h>
#include <stdio.h>
#define MAX_FIBONACCI_NUMBERS 100
// Structure to hold data shared between threads
struct ThreadData {
int sequence[MAX_FIBONACCI_NUMBERS];
int count;
};
// Function to generate Fibonacci sequence
void *generateFibonacci(void *arg) {
struct ThreadData *data = (struct ThreadData *)arg;
int n = data->count;
int a = 0, b = 1;
data->sequence[0] = a;
data->sequence[1] = b;
for (int i = 2; i < n; i++) {
int temp = a + b;
data->sequence[i] = temp;
a = b;
b = temp;
}
pthread_exit(NULL);
}
int main (){
int n;
printf("Fibonacci number:");
scanf("%d",&n);
pthread_t tid;
struct ThreadData data;
data.count=n;
pthread_create(&tid, NULL, generateFibonacci, (void *)&data);
pthread_join(tid, NULL);
printf("Fibonacci sequence:");
for (int i = 0; i < n; i++) {
printf(" %d", data.sequence[i]);
}
printf("\n");
return 0;
}
6.33
a
available resources variable
b
decrease count
available resources -= count;
increase count
available resources += count;
c
#include <pthread.h>
#define MAX_RESOURCES 5
int available_resources = MAX_RESOURCES;
pthread_mutex_t mutex;
int decrease_count(int count) {
if (available_resources < count)
return -1;
else {
pthread_mutex_lock(&mutex);
available_resources -= count;
pthread_mutex_unlock(&mutex);
return 0;
}
}
int increase_count(int count) {
pthread_mutex_lock(&mutex);
available_resources += count;
pthread_mutex_unlock(&mutex);
return 0;
}
hw3
7.8
The reason for the policy is that holding a spinlock while attempting to acquire a semaphore can lead to a deadlock scenario. example
- Process A holds a spinlock and is trying to acquire a semaphore.
- Process B holds the semaphore that Process A is trying to acquire and is trying to acquire the spinlock held by Process A.
8.20
- a:
- safely
- b
- unsafely
- the remain resource may not able to complete task
- c
- unsafely
- resource may not able to fulfill task request
- d
- safely
- e
- unsafely
- resource may not able to fulfill task request
- f
- safely
8.27
| task | allocation | max | need |
|---|---|---|---|
| A,B,C,D | A,B,C,D | A,B,C,D | |
| 1,2,0,2 | 4,3,1,6 | 3,1,1,4 | |
| 0,1,1,2 | 2,4,2,4 | 2,3,1,2 | |
| 1,2,4,0 | 3,6,5,1 | 2,4,1,1 | |
| 1,2,0,1 | 2,6,2,3 | 1,4,2,2 | |
| 1,0,0,1 | 3,1,1,2 | 2,1,1,1 |
- a
- safe
- b
- safe
8.30
semaphore bridgeAccess = 1
// northbound farmers
function crossBridgeNorth() {
wait(bridgeAccess)
deliver_to_neighbor_town();
signal(bridgeAccess)
}
// southbound farmers
function crossBridgeSouth() {
wait(bridgeAccess)
deliver_to_neighbor_town();
signal(bridgeAccess)
}
9.15
| Issues | Contiguous Memory | Allocation Paging |
|---|---|---|
| (a) External fragmentation | High | Low |
| (b) Internal fragmentation | Low | Less then contiguous memory |
| (c) Ability to share code | complex to implement. | Easy |
9.24
- a
- b
programming problems
7.15
#include <pthread.h>
#include <stdio.h>
#define MAX_FIBONACCI_NUMBERS 200
// Structure to hold data shared between threads
struct ThreadData {
int sequence[MAX_FIBONACCI_NUMBERS];
int count;
int current;
};
// Function to generate Fibonacci sequence
void *generateFibonacci(void *arg) {
struct ThreadData *data = (struct ThreadData *)arg;
int n = data->count;
data->sequence[0] = 1;
data->current=0;
data->sequence[1] = 1;
data->current=1;
for (int i = 2; i < n; i++) {
int temp = data->sequence[i-2] + data->sequence[i-1];
data->sequence[i] = temp;
data->current=i;
}
pthread_exit(NULL);
}
int main (){
int n;
printf("fb:");
scanf("%d",&n);
pthread_t tid;
struct ThreadData data;
data.count=n;
data.current=-1;
pthread_create(&tid, NULL, generateFibonacci, (void *)&data);
printf("Fibonacci sequence:");
int i=0;
while(1){
if(i<=data.current){
printf(" %d", data.sequence[i]);
i++;
}
if(i>=n)
break;
}
printf("\n");
pthread_join(tid, NULL);
return 0;
}
8.32
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#define FARMERS 25
// Structure to hold data shared between threads
struct ThreadData {
char *name;
int id;
};
pthread_mutex_t bridge_mutex;
//pthread_cond_t cond;
// Function to generate Fibonacci sequence
void *farmer(void *arg) {
struct ThreadData *data = (struct ThreadData *)arg;
int waitTime = (float)rand()/(float)(RAND_MAX)*1000*100;
//0 to 100 ms
pthread_mutex_lock(&bridge_mutex);
//run thought bridge
usleep(waitTime);
printf("%2d:%s Farmer cross in %2dms\n",data->id,data->name,waitTime/1000);
pthread_mutex_unlock(&bridge_mutex);
pthread_exit(NULL);
}
int main (){
pthread_t tid[FARMERS];
struct ThreadData data[FARMERS];
for(int i = 0;i<FARMERS;i++){
data[i].id=i;
if(i%2==0)
data[i].name="northbound";
else
data[i].name="southbound";
pthread_create(&tid[i], NULL, farmer, (void *)&data[i]);
}
for(int i = 0;i<FARMERS;i++){
pthread_join(tid[i], NULL);
}
pthread_mutex_destroy(&bridge_mutex);
return 0;
}
9.28
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main (int argc, char *argv[]){
if(argc<2){
printf("argment not fulfill");
return 0;
}
unsigned int address = atoi(argv[1]);
unsigned int page_size=1<<12;
unsigned int page_id=address/page_size;
unsigned int offset=address-page_size*page_id;
printf("page number=%d\n",page_id);
printf("offset=%d\n",offset);
return 0;
}
hw4
10.21
-
Memory access time = 100 ns
-
replace empty frame = 8ms
-
replace modified frame = 20ms
-
probability modified = 0.7
-
Page fault service time=
-
effective access time =
- 16399900ns *p+100ns<200 ns
- p=
10.24
| Page Reference | FIFO frames | LRU frames | Optimal(OPT) frames |
|---|---|---|---|
| 3 | 3 | 3 | 3 |
| 1 | 3,1 | 3,1 | 3,1 |
| 4 | 3,1,4 | 3,1,4 | 3,1,4 |
| 2 | 1,4,2 | 1,4,2 | 1,4,2 |
| 5 | 4,2,5 | 4,2,5 | 1,4,5 |
| 4 | 4,2,5 | 2,5,4 | 1,4,5 |
| 1 | 2,5,1 | 5,4,1 | 1,4,5 |
| 3 | 5,1,3 | 4,1,3 | 1,5,3 |
| 5 | 5,1,3 | 1,3,5 | 1,5,3 |
| 2 | 1,3,2 | 3,5,2 | 1,3,2 |
| 0 | 3,2,0 | 5,2,0 | 1,2,0 |
| 1 | 2,0,1 | 2,0,1 | 1,2,0 |
| 1 | 2,0,1 | 2,0,1 | 1,2,0 |
| 0 | 2,0,1 | 2,1,0 | 1,2,0 |
| 2 | 2,0,1 | 1,0,2 | 1,2,0 |
| 3 | 0,1,3 | 0,2,3 | 1,0,3 |
| 4 | 1,3,4 | 2,3,4 | 1,0,4 |
| 5 | 3,4,5 | 3,4,5 | 1,0,5 |
| 0 | 4,5,0 | 4,5,0 | 1,0,5 |
| 1 | 5,0,1 | 5,0,1 | 1,0,5 |
| Page Fault | 15 | 16 | 11 |
10.37
- causes
- Insufficient Physical Memory
- Poor Page Replacement Policies
- detection
- Page-Fault Rate
- solution
- local replacement policy
- If actual rate too low, process loses frame
- If actual rate too high, process gains frame
- local replacement policy
11.13
2069,1212,2296,2800,544,1618,356,1523,4965,3681
- FCFS
- 2069,1212,2296,2800,544,1618,356,1523,4965,3681
- SCAN
- 2150,2296,2800,3681,4965,2069,1618,1523,1212,544,256
- C-SCAN
- 2150,2296,2800,3681,4965,256,544,1212,1523,1618,2069
11.20
- a
- 2(1 block + 1 mirror)
- b
- 9(4 block + 1 parity + 3 block + 1 parity)
11.21
- a
- raid 1
- Faster
- raid 5
- Slower
- raid 1
- b
- raid 1
- Faster for small to moderate block sizes.
- raid 5
- Can be faster for large contiguous blocks
- raid 1
14.14
| Logical-to-Physical Mapping | Accessing Block 4 from Block 10 | |
|---|---|---|
| contiguous | start block + length | 1 |
| linked | linked list pointer | unknow |
| indexed | index block + block pointer | 1 ( index block is in memory) |
14.15
code
10.44
g++ hw4_10.44.cpp && ./a.out
#include <iostream>
#include <random>
#include <vector>
#include <queue>
#include <unordered_set>
#include <algorithm>
#include <array>
int FIFO(std::vector<int> &page_ref, int frame_size)
{
std::queue<int> page_frames;
std::unordered_set<int> frames;
int page_faults = 0;
for (int page : page_ref)
{
if (frames.find(page) == frames.end())
{
page_faults++;
if (page_frames.size() == frame_size)
{
int front = page_frames.front();
page_frames.pop();
frames.erase(front);
}
page_frames.push(page);
frames.insert(page);
}
}
return page_faults;
}
int LRU(std::vector<int> &page_ref, int frame_size)
{
std::vector<int> page_frames;
int page_faults = 0;
for (int i = 0; i < page_ref.size(); i++)
{
int page = page_ref[i];
for (int j = 0; j < page_frames.size(); j++)
{
if (page_frames[j] == page)
{
page_frames.push_back(page);
page_frames.erase(page_frames.begin() + j);
break;
}
}
if (page_frames.size() == 0 || page_frames.size() < frame_size && page_frames.back() != page)
{
page_faults++;
page_frames.push_back(page);
continue;
}
if (page_frames.back() != page)
{
page_faults++;
page_frames.erase(page_frames.begin());
page_frames.push_back(page);
}
}
return page_faults;
}
int OPT(std::vector<int> &page_ref, int frame_size)
{
std::vector<int> page_frames;
int page_faults = 0;
for (int i = 0; i < page_ref.size(); i++)
{
int page = page_ref[i];
auto p = std::find(page_frames.begin(), page_frames.end(), page);
if (p == page_frames.end())
{
page_faults++;
if (page_frames.size() < frame_size)
{
page_frames.push_back(page);
continue;
}
int index = 0;
int max = page_frames.size();
for (int j = 0; j < page_frames.size(); j++)
{
auto f = std::find(page_ref.begin() + i, page_ref.end(), page_frames[j]);
if (f - page_ref.begin() > max)
{
max = f - page_ref.begin();
index = j;
}
}
page_frames[index] = page;
}
}
return page_faults;
}
int main()
{
int n = 0;
printf("page frames:");
scanf("%d", &n);
std::vector<int> page_ref(50);
for (int i = 0; i < page_ref.size(); i++)
page_ref[i] = rand() % 10;
printf("page ref:");
for (int i = 0; i < page_ref.size(); i++)
printf("%d ", page_ref[i]);
printf("\n");
int page_faults1 = FIFO(page_ref, n);
int page_faults2 = LRU(page_ref, n);
int page_faults3 = OPT(page_ref, n);
printf("FIFO: %d\n", page_faults1);
printf("LRU: %d\n", page_faults2);
printf("OPT: %d\n", page_faults3);
return 0;
}
11.27
g++ hw4_11.27.cpp && ./a.out 2150
#include <iostream>
#include <random>
#include <vector>
#include <queue>
#include <unordered_set>
#include <algorithm>
#include <array>
#define MAX_DISK 5000
int FCFS(std::vector<int> &req, int head)
{
int dis = 0;
for (int request : req)
{
dis += abs(request - head);
head = request;
}
return dis;
}
int SCAN(std::vector<int> &req, int head)
{
int dis = 0;
std::sort(req.begin(), req.end());
auto it = std::lower_bound(req.begin(), req.end(), head);
std::vector<int> left(req.begin(), it);
std::vector<int> right(it, req.end());
for (auto it = right.begin(); it != right.end(); ++it)
{
dis += abs(*it - head);
head = *it;
}
if (!left.empty())
{
dis += abs(MAX_DISK - head);
head = MAX_DISK;
for (auto it = left.rbegin(); it != left.rend(); ++it)
{
dis += abs(*it - head);
head = *it;
}
}
return dis;
}
int C_SCAN(std::vector<int> &req, int head)
{
int dis = 0;
std::sort(req.begin(), req.end());
auto it = std::lower_bound(req.begin(), req.end(), head);
std::vector<int> left(req.begin(), it);
std::vector<int> right(it, req.end());
for (auto it = right.begin(); it != right.end(); ++it)
{
dis += abs(*it - head);
head = *it;
}
if (!left.empty())
{
dis += abs(MAX_DISK - head);
dis += MAX_DISK;
head = 0;
for (auto it = left.begin(); it != left.end(); ++it)
{
dis += abs(*it - head);
head = *it;
}
}
return dis;
}
int main(int argc, char **argv)
{
int n = argc > 1 ? atoi(argv[1]) : -1;
if (n == -1)
{
printf("Please enter init position\n");
return 0;
}
std::vector<int> req(1000);
for (int i = 0; i < req.size(); i++)
req[i] = rand() % MAX_DISK;
int distance1 = FCFS(req, n);
int distance2 = SCAN(req, n);
int distance3 = C_SCAN(req, n);
printf("FCFS: %d\n", distance1);
printf("SCAN: %d\n", distance2);
printf("C-SCAN: %d\n", distance3);
return 0;
}
tool
BitTorrent
tags: pdf BitTorrent
docker
Docker Image
Images are typically created from a base image (like a Linux distribution) and can be customized by adding your application code, configurations, and dependencies.
Docker Container
A Docker container is a running instance of a Docker image. It encapsulates the application code, libraries, and dependencies defined in the image, along with an isolated file system, network stack, and process space.
command
Working with Images:
docker images # List all locally available Docker images.
docker pull <image> # Download an image from a registry (e.g., Docker Hub).
docker build -t <tag> <path_to_Dockerfile> # Build a new Docker image from a Dockerfile.
docker rmi <image> # Remove a Docker image.
Working with Containers:
docker run [options] <image> # Create and start a new container based on the specified image.
docker ps # List all running containers.
docker ps -a # List all containers (including stopped ones).
docker start <container> # Start a stopped container.
docker stop <container> # Stop a running container.
docker restart <container> # Restart a container.
docker exec -it <container> <command> # Execute a command inside a running container.
Managing Docker Compose (for multi-container applications):
docker-compose up # Create and start containers defined in a docker-compose.yml file.
docker-compose down # Stop and remove containers created
Networking:
docker network ls # List all Docker networks.
docker network create <name> # Create a new Docker network.
docker network connect <network> <container> # Connect a container to a network.
docker network disconnect <network> <container> # Disconnect a container from a n
ffmpeg
tags: tool video editor
ffmpeg
get all frame
//%03d 如果小於三位數以三位數呈現
ffmpeg -i "path.mp4" "path_%03d.jpg"
get fps
ffmpeg -i "file"
images to video
ffmpeg -i "%03d.png" -c:v libx264 -vf fps=25 -pix_fmt yuv420p "out.mp4"
png to gif
ffmpeg -i %04d.png -vf palettegen=reserve_transparent=1 palette.png
ffmpeg -framerate 25 -i %04d.png -i palette.png -lavfi paletteuse=alpha_threshold=128 -gifflags -offsetting treegif.gif
m4a to mp3
ffmpeg -i in.m4a -c:v copy -c:a libmp3lame -q:a 4 out.mp3
cut video
4:00~4:10
ffmpeg -ss 00:04:00 -i qg.mp4 -to 00:04:10 -c copy output.mp4
replace aduio on video
ffmpeg -i video.mp4 -i audio.wav -map 0:v -map 1:a -c:v copy -shortest output.mp4
Add audio
ffmpeg -i video.mkv -i audio.mp3 -map 0 -map 1:a -c:v copy -shortest output.mkv
git
tags git
command line
git config --global user.email ""
git config --global user.name ""
git status
git init
git add --all
git commit -m "what do you done"
git branch -M main
git remote add origin https://github.com/lanx06/heroku.git
git push -u origin main
add 儲存 暫存
git add . and git add –all
git add .
只會新增或修改已存在檔案不會刪除
git add –all
所有檔案直接同步 如果有刪除檔案則會直接刪除 github上的版本
push 上傳
強制上傳
git push -f origin main更改上傳位置
git remote set-url origin https://github.com/USERNAME/OTHERREPOSITORY.git確認上傳位置
git remote -v
pull 同步檔案
git pull origin master
Clone or download
git clone https://github.com/lanx06/heroku.git
checkout index
git checkout index.py
checkout commit
git checkout commithash
branch 分支
checkout remote branch
git checkout -b branch_name origin/branch_name分支清單
git branch開啟分支
git branch branch_name合併分支
git merge {new-feature}刪除分支
git branch -d branch_name
其他
初始化專案
git init查看狀態
git status檢查差異
git diff將變更檔案放入暫存區
git add index.py使用 commit -m 提交變更
git -a -m 'init commit'查看歷史
git log --oneline放棄已經 commit 的檔案重回暫存區
git reset HEAD index.py
dot process
tags: graphviz
shields.io
tags: tool
快速製造好看的標籤
格式
參數
| 參數 | 功能 |
|---|---|
| color=ff00ff | 背景顏色 |
| labelColor=ff00ff | 標題顏色 |
| logoColor=ff00ff | logo color |
| logo=google | simple icon 上的logo名稱 |
| logoWidth=40 | 寬度 |
範例
https://img.shields.io/badge/note-hackMD
-5cb85c#綠色
?style=flat-square
&logo=hackhands
&logoColor=ffffff#白色
&labelColor=555555#灰色
mark down
<image src="https://img.shields.io/badge/-window-000000?style=for-the-badge&logo=github&logoColor=ffffff" width="80%">
ShortCuts
vscode sublime
| key | function |
|---|---|
| alt 1 | move to open file 1 |
| alt z | fold line |
| alt t | move to terminal |
| alt e | move to editor |
| alt s | move to setting |
| alt f | move to folder view |
| alt enter | when use find function will add cursor in result |
| alt shift f | auto tab 自動縮排 |
| alt shift 1 | remove slilce editer 刪除畫面分割 |
| alt shift 2 | slice editer 畫面分割 |
| alt shift 0 | change slilce way editer 更改畫面分割為上下或左右 |
| alt shift UpArrow | add cursor |
| alt shift DownArrow | add cursor |
| alt ctrl UpArrow | add cursor |
| alt ctrl DownArrow | add cursor |
| ctrl 1 | go to |
| ctrl d | find select word and add cursor |
| ctrl j | remove 換行 |
| ctrl g | go to line |
| ctrl p | go to file |
| ctrl i | 文字提示 |
| ctrl r | go to symbol |
| ctrl - | zoom out |
| ctrl = | zoom in |
| ctrl tab | switch file |
| ctrl / | 註解 |
| ctrl RightArrow | move by 英文單辭 |
| ctrl LeftArrow | move by 英文單辭 |
| ctrl shift c | copy file path |
| ctrl shift l | 選取範圍內的每行最後一個字加上鼠標 |
| ctrl shift p | all command |
| ctrl shift s | 另存新檔 |
| ctrl shift f | find in file |
MediBang Paint
| key | function |
|---|---|
| b | 筆刷 |
| w | 魔術棒 |
| m | 選取 方形 |
| l | 選取 |
| x | 顏色交換 |
| g | 油漆 |
| n | 圖形 |
| [ | 筆刷 變小 |
| ] | 筆刷 變大 |
| ctrl e | 向下合併 |
| ctrl t | 變形 |
| ctrl d | 取消選取 |
| ctrl shift i | 反轉選取 |
blender
| key | function |
|---|---|
| g | move objsct |
| r | rotate objsct |
| s | scale objsct |
| t | show/hiden function buttom |
| o | 力道擴散 |
| middle mouse | rotate view |
| middle mouse shift | move view |
| tab | 更改為 edit mode 或是 object mode 之類的 |
| ctrl a | 選取 |
| ctrl 3(number) | 細分 |
| shift a | 新增 |
| shift d | 複製 |
| shift a s | 新增 searh |
| edit mode ctrl 1 | 點 |
| edit mode ctrl 2 | 線 |
| edit mode ctrl 3 | 面 |
| edit mode u | uv unwarp |
| edit mode e | 創造 延伸 面點 |
| edit mode r | loop cut |
| edit mode i | inset face |
| edit mode k | knife cut |
| edit mode b | bevel (曲面) |
| edit mode b v | bevel (圓型 曲面) |
| edit mode mouse right alt | new point |
linux i3
| key | function |
|---|---|
| win(mod) number | swich desk |
| win(mod) d | new window |
| win(mod) q | close window |
| win(mod) e | swich h and v |
| win(mod) v | add next window with vertical way |
| win(mod) h | add next window with horizon way |
| win(mod) shift r | reload desk |
| win(mod) shift e | logout and shout down |
| win(mod) shift number | move window to number desk |
| ctrl p | preview command |
| ctrl n | next command |
vim in vscode
tags: vim tool editor
noraml
| 鍵 | 功能 |
|---|---|
| h | 左 |
| j | 下 |
| k | 上 |
| l | 右 |
| f1 | 啟用/停用vim |
| esc | to normal mode |
| alt f | to normal mode |
| i | to insert mode (insert) |
| a | to insert mode (append ) |
| o | add one line to top and insert mode |
| O | add one line to below and insert mode |
| : | to command mode |
| w | next word start |
| e | end of word |
| b | last word of start |
| / | searth word |
| n | move to next that searthed |
| p | past on below |
| P | past on top |
| u | undo |
| ctrl r | redo |
| $ | 移動到這一列的最後面字元處 |
| % | 移動到這一列的最前面字元處 |
| c | 重複刪除 例如向下刪除 10 列,[ 10 cj ] |
| v | select |
| V | line select |
| ctrl v | block select |
| shift v | line select |
| gg | start of file |
| shift g | end of file |
| number shift g | number line of file |
| ctrl w hjkl | move window focus |
| ctrl w HJKL | move window position |
| cgn | repalce word you search first use “n.” to redo on next word |
| m a-z | make book mark |
| ’ a-z | go to book mark |
| viw + ( or [ or { | select inner word |
| vaw + ( or [ or { | select outer word |
command mode
| 鍵 | 功能 |
|---|---|
| :number | go to line number |
| :Sex | browse the file system |
| :e . | browse the file system |
| :e filepath | open file |
| :sp | open window horizon |
| :sv | open window horizon |
| :vsp | open window vertial |
| :vs | open window vertial |
| :!termail_command | run termail_command on termal |
Sorry for the wait
omatase おまたせ お待たせ
omataseshimashita おまたせしました お待たせしました
おまたせいしました お待たせいしました
machi
| 非過去 | 過去 | |
|---|---|---|
| 肯定 | いきます | いきますした |
| いきます | いきますした | |
| 否定 | いきません | |
ex
先週のきんようひは ここにきましたか =上週五你來過這裡嗎?
せんしゆう の きんようひは
あした かこにきましたか
きょうのあさ=今日の朝=けす
けさあさ
いいえ shi
| ね | わ | れ |
|---|---|---|
| ne | wa | re |
| は | ほ | ま |
|---|---|---|
| ha | ho | mo |
| な | た |
|---|---|
| na | ta |
| て | と |
|---|---|
| te | to |
| あ | み |
|---|---|
| a | mi |
| ぬ | め |
|---|---|
| nu | me |



なにか に あります
いちばいかばくか にほの
3/14
こわは,たんのひてすか
たんせいかじょせいに
おくりもの するひてす
りかしている
りかいしてない(理解してない)
しつている(知っている)
こくはく(告白)
にほんこ(日本人)
しゆつせき しましたか
いきません(我不能去) いけません(我不能去)
けさ(今晨)
朝ごはん(早餐)
たいせう
あんとく
はつおん
きりくたさい きってくたさい みてそたさい
まえに(前) ここに(這裡) わたしのとこり
で(de)んし てんし
市場 (しじょう)
こちらは(這是)(Kochira wa)
もつと(更多的)
もっと
ありませんか(你有嗎?)
3/21
たいへん(非常)
おへれて すみません (抱歉我遲到了)
まだ(仍然)
さむい あたたか あつい
電話(でんわ) けをつけて
からだ(身體) ください
すりに(扒手)
なにか(某物) しつもん(質問)は ありませんか?(有嗎?) ありますんか?(有沒有?)
ありません(沒有) あります(有)
しまつた(完成的有) しませんでした(完成的沒有)
やるき やる気(動機) やるきかあります(我有動力)
おましろい(面白い)有趣的 つまらない(無聊的)
3/28
いち えん=1円 なん えん=何円
4/25
おととい 前天 きのう きよう あした
おはようございます 早安 こんにちは 你好 こんばんは 晚安
です でした ます ました
| now | past | |
|---|---|---|
| yes | たか いだす | たか かつたです |
| no | たか くないです |
| now | past | |
|---|---|---|
| yes | きれい いだす | たか かつたです |
| no | きれい ではありません |